最新リモートセンシングデータセットにおける深層学習TransformerとCNNの性能評価・分析
2025-08-13
引用:http://arxiv.org/pdf/2508.02871v1
著者と所属
- J. Alex Hurt
- Trevor M. Bajkowski
- Grant J. Scott
- Curt H. Davis (所属機関は論文中に明記されていません)
論文概要
この論文「Evaluation and Analysis of Deep Neural Transformers and Convolutional Neural Networks on Modern Remote Sensing Datasets」は、リモートセンシング分野における重要な課題である衛星画像からの物体検出に焦点を当てた研究です。 本研究では、近年コンピュータビジョン分野で大きな注目を集めているTransformerアーキテクチャと、従来から標準的な技術であった**畳み込みニューラルネットワーク(CNN)**の性能を、衛星画像という特殊なドメインで体系的に比較・分析しています。
研究の目的: 本研究の主な目的は、衛星画像における物体検出タスクで、TransformerとCNNのどちらが優れているのか、どのような特性を持つのかを明らかにすることです。また、性能だけでなく計算コスト(学習時間)とのトレードオフを解明し、リモートセンシング分野の研究者や開発者が自身の目的に合ったモデルを選択するための実践的な指針を提供することも目指しています。
研究の背景: 2012年にAlexNetが登場して以来、CNNは画像認識の分野を席巻してきました。しかし近年、自然言語処理分野で生まれたTransformerアーキテクチャが画像認識にも応用され(Vision Transformerなど)、多くのタスクでCNNを凌駕する性能を示し始めています。 ただし、これらの成果の多くは一般的な地上からの写真データセットで得られたものです。衛星画像は、上空からの俯瞰的な視点、多様なスケール、特有の物体配置など、地上写真とは異なる特徴を持っています。そのため、Transformerが衛星画像に対しても同様の優位性を発揮できるかは明らかではありませんでした。この研究は、そのギャップを埋めるための大規模な比較実験を行ったものです。
提案手法のハイライト: 本研究は、特定の新技術を提案するのではなく、徹底的な比較評価そのものに価値があります。そのハイライトは以下の通りです。
- 網羅的なモデル選定: Transformerベースのモデル5種とCNNベースのモデル6種、合計11種類の主要な物体検出モデルを評価対象としています。
- 多様なデータセットでの評価: サイズや複雑さが異なる3つの公開リモートセンシングデータセット(RarePlanes, DOTA, xView)を用いることで、モデルの汎用性やデータ依存性を深く分析しています。
- 詳細な性能分析: 単純な精度比較だけでなく、学習時間やモデルの複雑さといった実用的な側面からの分析も行っています。
 図1: 本研究で評価に使用された3つのデータセットのサンプル画像。上から順にRarePlanes(航空機)、DOTA(多様な物体)、xView(高密度の物体)。データセットごとに物体の種類、サイズ、密度が大きく異なることがわかります。
図1: 本研究で評価に使用された3つのデータセットのサンプル画像。上から順にRarePlanes(航空機)、DOTA(多様な物体)、xView(高密度の物体)。データセットごとに物体の種類、サイズ、密度が大きく異なることがわかります。
関連研究
先行研究のレビュー
本研究では、物体検出における2大アーキテクチャであるCNNとTransformerから、代表的なモデルが選定されています。
-
CNNベースのモデル(6種):
- Faster R-CNN: 「物体がありそうな領域」をまず提案し、その領域を詳しく分類する2段階の検出手法の代表格。
- SSD (Single Shot Detector): 1回の処理で物体の位置とクラスを同時に予測する高速な1段階検出器。
- RetinaNet: 1段階検出器の課題であった「簡単な背景」と「重要な物体」の学習のアンバランスを「Focal Loss」という工夫で解決。
- YOLOv3, YOLOX: 「You Only Look Once」の名の通り、非常に高速なリアルタイム物体検出で有名なシリーズ。
- FCOS: アンカーボックス(物体の初期位置の候補)を使わないアンカーフリーの手法で、設計をシンプルにしました。
- ConvNeXt: Transformerの設計思想をCNNに取り入れ、性能を向上させた新しいCNNアーキテクチャ。
-
Transformerベースのモデル(5種):
- Vision Transformer (ViT): 画像を単語のようにパッチに分割し、Transformerに入力する手法で、画像認識におけるTransformerの可能性を示した先駆的なモデル。
- SWIN Transformer: ViTの計算コストを改善し、階層的な特徴を捉えられるようにした、より実用的なTransformerモデル。
- DETR (DEtection TRansformer): 物体検出のプロセス全体をTransformerで構築した最初のEnd-to-Endモデル。
- Deformable DETR: DETRの性能と収束速度を、より効率的なアテンション機構で改善したモデル。
- CO-DETR: DETR系の学習効率をさらに高めるための新しい訓練手法を導入した最新のモデル。
| Detector | Type | Backbone | Parameters (M) | APCOCO | Release Year |
|---|---|---|---|---|---|
| ConvNeXt SSD RetinaNet FCOS YOLOv3 YOLOX | Two-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN | ConvNeXt-S VGG-16 ResNeXt-101 ResNeXt-101 DarkNet-53 YOLOX-X | 67.09 36.04 95.47 89.79 61.95 99.07 | 51.81 29.5 41.6 42.6 33.7 50.9 | 2022 2016 2017 2019 2018 2021 |
| ViT DETR Deformable DETR SWIN CO-DETR | Transformer Transformer Transformer Transformer Transformer | ViT-B ResNet-50 ResNet-50 SWIN-T SWIN-L | 97.62 41.30 40.94 45.15 218.00 | N/A2 40.1 46.8 46.0 64.1 | 2020 2020 2020 2021 2023 |
表1: 本研究で調査された検出手法の比較。モデルの種類、バックボーン(特徴抽出部)、パラメータ数、COCOデータセットでの性能(AP)、発表年がまとめられています。
先行研究と本研究の違い
個別のモデルを開発する先行研究に対し、本研究はこれらの多様なモデルをリモートセンシングという特定の応用ドメインで横断的に評価・分析した点に大きな違いがあります。これにより、一般的なデータセットでは見えてこない、衛星画像特有の課題に対する各モデルの振る舞いを明らかにしました。
論文の新規性と貢献
新規性
本研究は、以下の点で既存の研究と比較して新しい視点を提供しています。
- 初の大規模比較: リモートセンシング分野において、TransformerとCNNの物体検出性能をこれほど大規模かつ体系的に比較した研究は初めてです。
- 多様な条件下での検証: 特性の異なる3つのデータセットを用いることで、モデルがどのような状況で強く、どのような状況で弱いのかを多角的に評価しています。
- 最新モデルの網羅: 2023年に発表されたCO-DETRなど、最新のアーキテクチャを含む11ものモデルを対象としており、非常に網羅的です。
貢献
本研究は、以下の点で学術的および実用的な貢献をしています。
- モデル選択の指針提供: リモートセンシング分野の研究者や実務者が、プロジェクトの要件(精度、速度など)に応じて最適なモデルを選択するための具体的なデータと洞察を提供します。
- Transformerの有効性の実証: Transformerモデルが衛星画像に対しても高いポテンシャルを持つことを実証し、この分野での応用研究を加速させます。
- 学習済みモデルの公開: 本研究で訓練された33個のモデルの重みを公開しており、他の研究者が転移学習などで活用できるため、コミュニティ全体の発展に直接的に貢献します。
評価・考察
評価方法
提案手法の有効性を検証するために、以下の評価方法を採用しました。
- 分析方法: Transformerベースの5モデルとCNNベースの6モデルの性能を、3つのデータセットで比較。
- データセット:
- RarePlanes: 航空機に特化した小規模データセット(約2.5万オブジェクト)。
- DOTA: 16クラスの多様な物体を含む中規模データセット(約28万オブジェクト)。
- xView: 60クラスの物体が密集して存在する大規模かつ高難度なデータセット(約100万オブジェクト)。
- 評価指標:
- Optimal F1 Score: 適合率と再現率のバランスを示す指標で、モデルの総合的な検出精度を表します。
- AP (Average Precision): 物体検出タスクで標準的に用いられる性能指標。AP50は、物体位置の重なり具合(IoU)が50%以上で正解とみなす場合のAP。
- AR (Average Recall): どれだけ見逃しなく物体を検出できたかを示す再現率。
研究成果
研究の結果、以下の重要な知見が得られました。
1. Transformerはリモートセンシングでも強い 全てのデータセットにおいて、最も性能が高かったのはTransformerベースのモデルでした。
- RarePlanes (小規模): SWIN Transformerが最高のF1スコア(81.70%)を達成。
- DOTA (中規模): CO-DETRが最高のF1スコア(73.53%)を達成。
- xView (大規模): SWIN Transformerが最高のF1スコア(34.04%)を達成。
| Model | P | F1 | AP | AP50 | AR | AR50 |
|---|---|---|---|---|---|---|
| SWIN | 45 | 81.70 | 59.04 | 73.71 | 61.94 | 74.47 |
| YOLOX | 99 | 77.14 | 54.84 | 66.27 | 58.22 | 68.71 |
| CO-DETR | 218 | 70.71 | 56.60 | 67.95 | 79.74 | 97.59 |
表3 (一部抜粋): RarePlanesデータセットでの性能。SWIN TransformerがF1スコアでトップ。一方、CO-DETRは見逃しが極端に少ない(AR50が97.59%)という特徴を示しました。
2. 性能と計算コストはトレードオフの関係にある 高い性能を発揮するモデルほど、学習に時間がかかる傾向が見られました。
- CO-DETR: DOTAデータセットで最高性能を発揮しましたが、学習速度は最も遅い(5.02 FPS)。
- YOLOX: CO-DETRに匹敵する性能を、約3倍の速さ(14.74 FPS)で達成し、バランスに優れています。
- YOLOv3: 性能は中程度ですが、非常に高速(45.5 FPS)で、リアルタイム性が求められる応用に向いています。
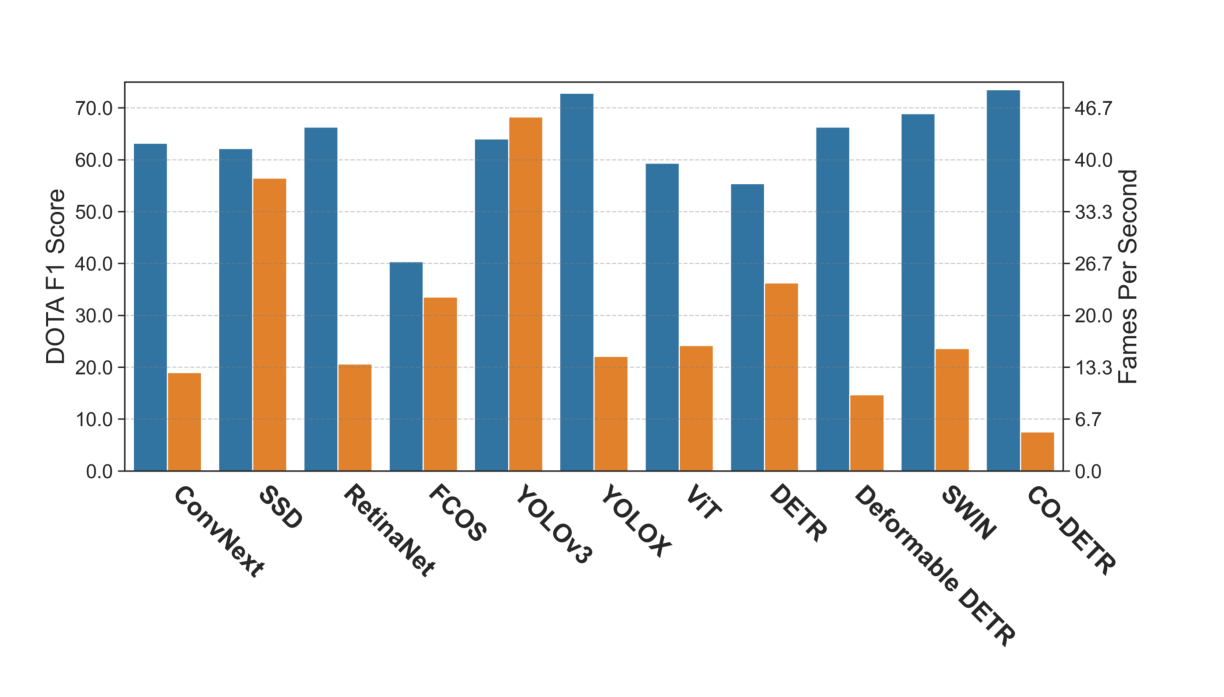 図3: DOTAデータセットにおけるF1スコア(青)と学習速度(オレンジ, FPS)の比較。性能が高いモデル(例:CO-DETR)は遅く、速いモデル(例:YOLOv3)は性能がやや低いというトレードオフの関係が明確に示されています。
図3: DOTAデータセットにおけるF1スコア(青)と学習速度(オレンジ, FPS)の比較。性能が高いモデル(例:CO-DETR)は遅く、速いモデル(例:YOLOv3)は性能がやや低いというトレードオフの関係が明確に示されています。
3. Transformerはより安定した性能を発揮する CNNモデルの中には、データセットによって性能が大きく変動するものがありましたが(例:FCOS)、Transformerモデルは比較的安定した性能を示す傾向がありました。特に SWIN, YOLOX, CO-DETR の3つは、どのデータセットでも常にトップクラスの性能を維持しました。
4. ケーススタディ: CNNバックボーン vs Transformerバックボーン 同じ検出アルゴリズム(RetinaNet)で、バックボーン(特徴抽出部)をCNN(ResNeXt-101)とTransformer(ViT)で入れ替えて比較しました。
- 中規模のDOTAデータセットでは、CNN版の方が高性能でした。
- 大規模なxViewデータセットでは、両者の性能差は縮まりました。 これは、**「Transformerは性能を最大限に引き出すために、より多くのデータを必要とする」**という先行研究の結果を裏付けるものです。
応用例と今後の展望
応用可能性
本研究の成果は、衛星画像を利用する様々な実用分野への応用が期待されます。
- 防災・災害対応: 地震や洪水後の建物の被害状況を自動で把握する。
- 環境モニタリング: 違法な森林伐採や都市の拡大を広範囲で監視する。
- 安全保障: 特定の施設や車両の活動を自動追跡・分析する。
- 農業・漁業: 作物の生育状況や養殖場の管理を効率化する。
ビジネス的展望
本研究の成果は、以下のビジネス分野での利用が期待されます。
- 新規製品やサービスの開発: 高精度な衛星データ解析を組み込んだ新しい地理情報サービスや保険査定ツール。
- 運用効率化: 広大なインフラ(パイプライン、送電網など)の点検・管理を自動化し、コストを削減。
- 市場への影響: 衛星データ活用のハードルを下げ、農業、金融、不動産など多様な業界での市場を創出・拡大する。
今後の課題
本研究は大きな貢献をしましたが、さらなる発展のためには以下の課題が考えられます。
- 計算コストの削減: 高性能なTransformerモデルを、より少ない計算資源で効率的に学習・運用する技術。
- 少数クラス・微小物体への対応: データセット内に数少ないクラスや、非常に小さな物体をいかに高精度で検出するか。
- 汎用性の向上: 特定の地域やセンサーで学習したモデルを、異なる条件下でも安定して機能させるための研究。
結論
この論文は、リモートセンシング(衛星画像)における物体検出タスクにおいて、Transformerアーキテクチャが従来のCNNを凌駕する性能ポテンシャルを持つことを、広範かつ体系的な実験を通じて明確に示しました。
特に、SWIN Transformer、YOLOX、CO-DETRといったモデルが、データセットの特性によらず安定して高い性能を発揮することがわかりました。一方で、その高性能は学習時間の増加という計算コストを伴うため、実用化の際には性能とコストのトレードオフを考慮したモデル選択が不可欠であることも明らかにされました。
本研究は、リモートセンシング分野における次世代の物体検出技術の方向性を示す重要なマイルストーンであり、この分野の研究開発を加速させる貴重な知見とリソース(学習済みモデル)を提供しています。
注釈
- Transformer: 文脈を読んで単語の意味を捉えるように、画像内の各部分(パッチ)間の関連性を学習するモデル。元々は自然言語処理で開発されました。
- CNN (畳み込みニューラルネットワーク): 画像を小さなフィルターでスキャンするようにして、エッジや模様などの局所的な特徴を抽出するのが得意なネットワーク。画像認識の標準的モデルです。
- 物体検出 (Object Detection): 画像の中から「何が(クラス)」「どこに(位置)」あるかを特定するタスクです。
- リモートセンシング (Remote Sensing): 航空機や人工衛星から地表などを観測する技術。本研究では特に衛星画像が対象です。
- F1スコア: モデルの「見逃しの少なさ(再現率)」と「誤検出の少なさ(適合率)」をバランス良く評価する指標。
- AP (Average Precision): 物体検出モデルの総合的な性能を評価するためによく使われる指標で、値が高いほど高性能です。
関連記事
2025-08-13
本研究は、深層学習モデルが皮膚の組織画像から患者の自己申告人種を予測できるかを検証し、AIが意図せず学習する可能性のある人口統計学的バイアスについて調査したものです。アテンション分析により、モデルが『表皮』などの特定の組織構造を手がかり(ショートカット)に人種を予測していることを明らかにしました。この結果は、医療AIを公平に社会実装するためのデータ管理とバイアス緩和の重要性を示唆しています。
2025-08-13
本論文では、最大200ページに及ぶ長い文書から特定の情報を探し出す能力を測定する新しいベンチマーク「Document Haystack」を提案します。このベンチマークは、文書内に意図的に埋め込まれたテキスト情報や画像情報(「針」)を、Vision Language Model(VLM)がどれだけ正確に見つけ出せるかを評価します。実験の結果、現在のVLMはテキストのみの文書では高い性能を発揮するものの、画像化された文書や、テキストと画像が混在する情報では性能が大幅に低下することが明らかになりました。これは、VLMの長文・マルチモーダル文書理解能力における今後の研究課題を示唆しています。
2025-08-13
本論文は、GoogleのGemini 2.5 Proを活用し、追加学習なしで歩行者の横断意図を予測するゼロショット手法「BF-PIP」を提案します。従来のフレームベースの手法とは異なり、短い連続ビデオと自車速度などのメタデータを直接利用することで、73%という高い精度を達成し、コンテキスト理解に基づく強固な意図予測の可能性を示しました。