フレームの先を見る:生の時系列ビデオとマルチモーダルな手がかりによるゼロショット歩行者意図予測
2025-08-13
引用:http://arxiv.org/pdf/2507.21161v1
著者と所属
- Ying Liu: テキサス工科大学 コンピュータサイエンス学部
- Pallavi Zambare: テキサス工科大学 コンピュータサイエンス学部
- Venkata Nikhil Thanikella: テキサス工科大学 コンピュータサイエンス学部
論文概要
この論文「Seeing Beyond Frames: Zero-Shot Pedestrian Intention Prediction with Raw Temporal Video and Multimodal Cues」は、自動運転技術における重要な課題である 歩行者の横断意図予測 に焦点を当てた研究です。 本研究では、この課題を解決するため、Googleの最新マルチモーダル大規模言語モデル(MLLM)である Gemini 2.5 Pro を活用した、新しいゼロショットアプローチ「BF-PIP」を提案しています。
研究の目的: 本研究の主な目的は、従来の意図予測モデルが抱える「大量の事前学習データが必要」「新しい環境への適応力が低い」といった問題を克服することです。そのために、追加の学習を一切行わない「ゼロショット学習」によって、連続したビデオ映像と複数の情報源(マルチモーダルな手がかり)から、直接かつ高精度に歩行者の意図を予測するフレームワークを構築することを目指しています。
研究の背景: 自動運転車が都市部を安全に走行するためには、歩行者の次の行動、特に「道を渡るかどうか」を正確に予測することが不可欠です。これまでの研究では、RNNやTransformerといったモデルを用いて歩行者の動きを予測してきましたが、これらの手法は特定のデータセットで学習させる必要があり、学習データにない未知の状況への対応が困難でした。 近年、GPT-4VのようなMLLMが登場し、ゼロショットでの予測が可能になりつつありますが、これらもまだ静止画の連続(フレームシーケンス)を処理しており、歩行者の「ためらい」や「視線の動き」といった、連続的なビデオだからこそ捉えられる微妙なニュアンスを見逃す可能性がありました。
提案手法のハイライト: 本研究で提案する「BF-PIP」の最も重要な特徴は以下の通りです。
- 連続ビデオの直接処理: 従来の静止画ベースではなく、短いビデオクリップを直接入力として利用します。これにより、動きの連続性や時間的な文脈を豊かに捉え、より自然な形で状況を理解できます。
- ゼロショット推論: Gemini 2.5 Proの強力な汎用能力を活かし、特定のデータセットに対する追加学習やファインチューニングを一切行いません。これにより、開発コストを削減し、未知のシナリオにも迅速に対応できます。
- マルチモーダルな手がかりの活用: ビデオ映像に加えて、歩行者の位置を示すバウンディングボックスや自車の速度といった、文脈を理解するための追加情報をプロンプトに組み込むことで、予測精度を向上させます。
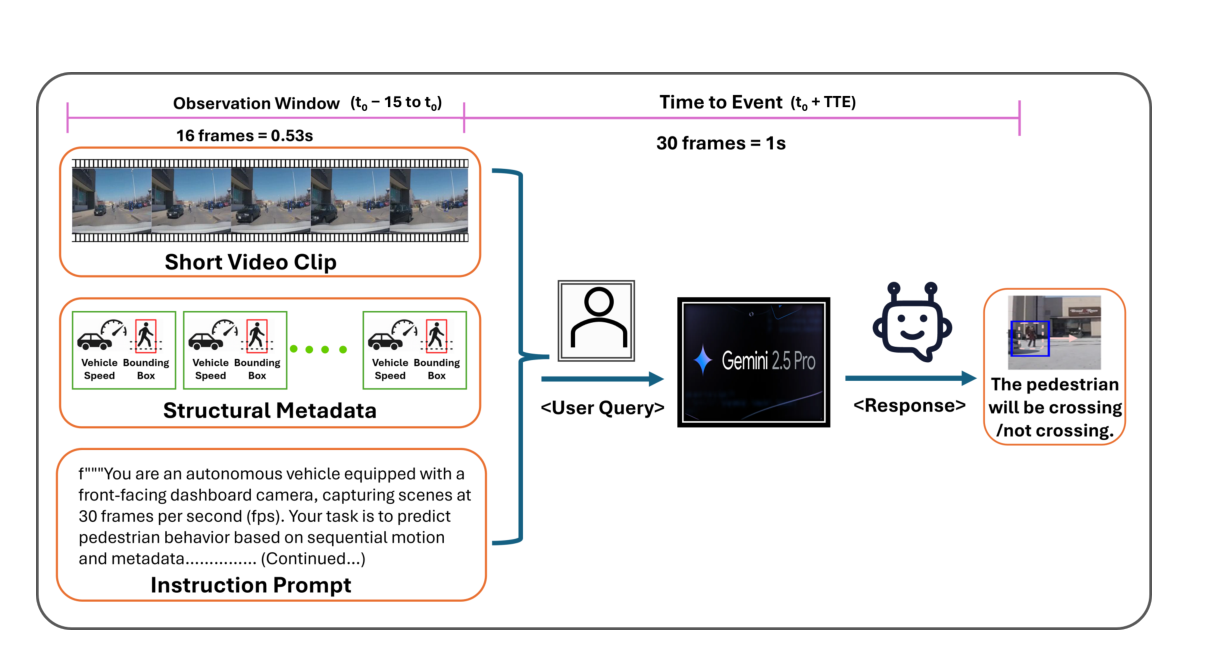 図1: BF-PIPフレームワークの概要図。短いビデオクリップ、バウンディングボックス、自車速度といったマルチモーダルな情報をGemini 2.5 Proへのプロンプトとして入力し、歩行者の横断意図(Crossing/Not Crossing)をゼロショットで予測します。
図1: BF-PIPフレームワークの概要図。短いビデオクリップ、バウンディングボックス、自車速度といったマルチモーダルな情報をGemini 2.5 Proへのプロンプトとして入力し、歩行者の横断意図(Crossing/Not Crossing)をゼロショットで予測します。
関連研究
先行研究のレビュー
- 従来手法 (RNN, GCN, Transformerベース): これらのモデルは、歩行者の軌道や姿勢といった時系列データを学習することで意図を予測します。高い性能を出すものもありますが、大規模なラベル付きデータセットでの教師あり学習が必須であり、般化性能に課題がありました。
- MLLMベース手法 (GPT4V-PBP, OmniPredict): GPT-4VやGPT-4oといったMLLMを用いてゼロショットで意図予測を行う研究です。大きな進歩をもたらしましたが、入力が静止画のシーケンスに留まっており、ビデオが持つ連続的な動きの情報を十分に活用できていませんでした。
先行研究と本研究の違い
本研究は、先行するMLLMベースの手法から一歩進んで、生の連続したビデオクリップを直接モデルに入力する点に大きな違いがあります。これにより、先行研究では捉えきれなかった、ためらいや視線移動といった時間的なダイナミクスを捉えることが可能になり、より現実に近い状況認識に基づいた予測を実現します。
論文の新規性と貢献
新規性
本研究は、以下の点で既存の研究と比較して新しい視点を提供しています。
- 新規性1: MLLM(Gemini 2.5 Pro)を用いて、生の連続ビデオクリップから直接、かつゼロショットで歩行者の意図を予測する世界初のフレームワークを提案しました。
- 新規性2: ビデオ情報に、バウンディングボックスや自車速度といった構造化されたメタデータを組み合わせた、効果的なマルチモーダルプロンプトを設計し、モデルの時空間理解能力と推論精度を大幅に向上させました。
貢献
本研究は、以下の点で学術的および実用的な貢献をしています。
- 貢献1: 自動運転システムの知覚モジュールの開発において、コストと時間のかかる再学習を不要にするアプローチを提示しました。これにより、よりアジャイル(俊敏)な開発が可能になります。
- 貢献2: 標準的なベンチマークデータセット(JAAD)において、既存の最先端MLLMベース手法を上回る精度を達成し、ビデオを直接利用するゼロショット推論の有効性を実証しました。
提案手法の詳細
手法の概要
この論文では、BF-PIP (Beyond Frames Pedestrian Intention Prediction) を提案しています。この手法は、Gemini 2.5 Proが持つ、ビデオ・画像・テキストを単一のプロンプトで処理できる高度なマルチモーダル能力を最大限に活用します。
手法の構成
提案手法は、以下のステップで構成されています。
- タスクの定義: 歩行者の横断意図予測を「横断する」か「横断しない」かの二値分類問題として設定します。予測は、行動が起こる1秒前(30フレーム前)の時点で行い、その直前の約0.5秒間(16フレーム)のビデオクリップを観測データとして使用します。
- マルチモーダル入力の準備:
- ショートビデオクリップ: 観測対象となる16フレームの連続したビデオを用意します。
- バウンディングボックス座標: 歩行者の位置を特定するための矩形領域の座標。映像に直接描画する(注釈あり)、あるいはテキスト情報として与えます。
- 自車速度: 自車の速度(加速、減速、定速など)を文脈情報として追加します。
- プロンプトの設計と推論戦略:
- Gemini 2.5 Proに「あなたは自動運転車のカメラです」という役割を与えるロールプレイプロンプトを採用。
- タスク内容、入力データの形式(16フレームのビデオ、バウンディングボックス等)、そして「歩行者の姿勢や動き、周囲の状況を分析しなさい」といった思考のステップを明確に指示します。
- この構造化されたプロンプトとビデオを入力としてGemini 2.5 Proに与え、推論を実行させます。出力は一貫性を保つためにJSON形式に指定します。
評価・考察
評価方法
提案手法の有効性を検証するために、以下の評価方法を採用しました。
- データセット: 自動運転研究で広く利用される JAAD (Joint Attention in Autonomous Driving) データセットの、特に横断行動に焦点を当てた
JAADbehサブセットを使用しました。 - 実験設定: テスト用の126クリップを用いてゼロショット推論を評価。歩行者の位置が明示された「注釈あり(Annotated)」ビデオと、何も描画されていない「注釈なし(Unannotated)」ビデオの2つの条件で実験を行いました。
- 評価指標: 精度(Accuracy)、AUC(Area Under the ROC Curve)、F1スコア、適合率(Precision)、再現率(Recall)の5つの標準的な指標を用いて性能を評価しました。
研究成果
研究の結果、以下の重要な知見が得られました。
定量的結果 BF-PIPは、追加学習なしにもかかわらず、既存の特化モデルやMLLMベースの手法と比較して非常に高い性能を示しました。
- 最高の精度: 提案手法は精度73%、AUC 0.76を達成し、同じMLLMベースの最先端モデルであるOmniPredict(精度67%)を6%上回りました。
- 高い信頼性: 特に適合率(Precision)は0.96という驚異的な値を記録。これは、モデルが「横断する」と予測した場合、その予測が非常に信頼できることを意味します。
| Models | Year | Model Variants | Inputs | JAAD-beh |
|---|---|---|---|---|
| Models | Year | Model Variants | I B P S V Extra Info. | ACC AUC F1 P R |
| MultiRNN [3] | 2018 | GRU | ✓ ✓ ✓ – – | 0.61 0.50 0.74 0.64 0.86 |
| ... | ... | ... | ... | ... |
| GPT4V-PBP [15] | 2023 | MLLM | ✓ ✓ – – – Text | 0.57 0.61 0.65 0.82 0.54 |
| OmniPredict [14] | 2024 | MLLM | ✓ ✓ – ✓ – Text | 0.67 0.65 0.65 0.66 0.65 |
| BF-PIP(Ours) | 2025 | MLLM | – ✓ – ✓ ✓ Text | 0.73 0.77 0.80 0.96 0.69 |
表1: 既存の最先端手法との性能比較。BF-PIP(太字)は、ビデオ(V)を主要な入力とし、精度(ACC)、AUC、F1スコア、適合率(P)において高い性能を達成しています。
定性的結果 モデルがどのように判断しているかを分析したところ、Gemini 2.5 Proは人間のように文脈を深く理解していることがわかりました。
- 複合的な状況判断: 図2の例では、モデルは歩行者が横断歩道近くにいること、車道の方へ体を傾けていること、車が来ていないか確認している視線の動きなど、複数の手がかりを統合して「横断する」と正しく予測しました。
 図2: 歩行者横断意図の定性的分析例。モデルは、歩行者の姿勢(前かがみ)、視線の方向(交通の確認)、微細な動き(横断歩道への一歩)といった複数の要素を捉え、総合的に横断意図を判断しています。
図2: 歩行者横断意図の定性的分析例。モデルは、歩行者の姿勢(前かがみ)、視線の方向(交通の確認)、微細な動き(横断歩道への一歩)といった複数の要素を捉え、総合的に横断意図を判断しています。
アブレーションスタディ 入力する情報の種類を変えて、どの要素が性能に貢献しているかを調べました。
- ビデオと速度情報の重要性: 注釈付きビデオ(AV)と自車速度(S)を組み合わせた場合に、最高の精度(0.73)とF1スコア(0.80)を達成しました。このことから、視覚的な誘導(バウンディングボックス)と、動きの文脈(自車速度)の両方が、高精度な予測に不可欠であることが確認されました。
| Input Modality | ACC | AUC | F1 | P | R |
|---|---|---|---|---|---|
| UV (注釈なしビデオ) | 0.65 | 0.62 | 0.74 | 0.96 | 0.60 |
| UV + S (+速度) | 0.70 | 0.74 | 0.78 | 0.97 | 0.65 |
| AV (注釈付きビデオ) | 0.64 | 0.61 | 0.73 | 0.95 | 0.59 |
| AV + S (+速度) | 0.73 | 0.76 | 0.80 | 0.96 | 0.69 |
表2: 入力モダリティに関するアブレーションスタディ。注釈付きビデオ(AV)に自車速度(S)を追加した組み合わせが最も高い性能を示しました。
応用例と今後の展望
応用可能性
本研究の成果は、さまざまな分野への応用が期待されます。
- 応用例1: より安全で信頼性の高い自動運転車の知覚・予測システム。
- 応用例2: 交差点や道路の安全性を高めるための**インテリジェント交通システム(ITS)**や交通監視システム。
ビジネス的展望
本研究の成果は、以下のビジネス分野での利用が期待されます。
- 新規製品やサービスの開発: 人間のドライバーのように状況を理解し、危険を予測できる高度な運転支援システムや完全自動運転システムの実現。
- 運用効率化: データのラベリングやモデルの再学習にかかる膨大なコストと時間を削減し、AI開発のサイクルを大幅に短縮。
- 市場への影響: ゼロショット学習をベースとしたアジャイルなAI開発手法を交通分野にもたらし、技術的な競争優位性を確立する可能性があります。
今後の課題
本研究は大きな成功を収めましたが、さらなる発展のためにはより複雑なシナリオへの対応が今後の課題となります。例えば、複数の歩行者が同時に存在する状況や、悪天候・夜間といった厳しい条件下での性能の検証、そしてリアルタイム性を保証するための計算コストの最適化などが挙げられます。
結論
この論文では、Gemini 2.5 Proのマルチモーダル能力を活用し、生の連続ビデオクリップから歩行者の横断意図をゼロショットで予測する新しいフレームワーク「BF-PIP」を提案しました。 追加学習を一切行わずに既存の最先端手法を上回る高い精度を達成した本研究は、静的なフレームの分析から脱却し、時間的な文脈を豊かに捉えることの重要性を示しました。この成果は、より安全で効率的な自動運転システムを実現するための重要な一歩であり、今後のAI開発に大きな影響を与えることが期待されます。
注釈
- ゼロショット学習 (Zero-shot Learning): モデルが訓練データに含まれていないタスクやカテゴリを、事前の追加学習なしに実行する能力。高い汎用性を持つことを示す。
- マルチモーダルLLM (MLLM): テキスト、画像、ビデオ、音声など、複数の異なる種類の情報(モダリティ)を同時に理解し、処理できる大規模言語モデル。本研究ではGemini 2.5 Proが使用された。
- バウンディングボックス (Bounding Box): 画像や映像の中で、特定の物体(この研究では歩行者)を囲む四角形の領域。物体の位置と大きさを示す。
- プロンプト (Prompt): 大規模言語モデルに対して、特定のタスクを実行させるための指示や文脈を与えるテキスト入力。プロンプトの設計がモデルの性能を大きく左右する。
- アブレーションスタディ (Ablation Study): モデルやシステムの構成要素を一つずつ取り除き、性能がどのように変化するかを調べることで、各要素の重要度を分析する実験手法。
- JAAD (Joint Attention in Autonomous Driving): 自動運転研究で広く使われる、歩行者の行動や意図に関する詳細な注釈が付与されたビデオデータセット。
関連記事
2025-08-13
本論文は、衛星画像などのリモートセンシングデータを用いた物体検出タスクにおいて、近年注目を集めるTransformerモデルと、従来主流であったCNNモデルの性能を大規模かつ体系的に比較・分析した研究です。3つの異なる特性を持つデータセット上で11種類のモデルを評価し、TransformerがCNNを上回る性能を発揮する可能性と、その際の学習コストとのトレードオフを明らかにしました。
2025-08-13
本研究は、深層学習モデルが皮膚の組織画像から患者の自己申告人種を予測できるかを検証し、AIが意図せず学習する可能性のある人口統計学的バイアスについて調査したものです。アテンション分析により、モデルが『表皮』などの特定の組織構造を手がかり(ショートカット)に人種を予測していることを明らかにしました。この結果は、医療AIを公平に社会実装するためのデータ管理とバイアス緩和の重要性を示唆しています。
2025-08-13
本論文では、最大200ページに及ぶ長い文書から特定の情報を探し出す能力を測定する新しいベンチマーク「Document Haystack」を提案します。このベンチマークは、文書内に意図的に埋め込まれたテキスト情報や画像情報(「針」)を、Vision Language Model(VLM)がどれだけ正確に見つけ出せるかを評価します。実験の結果、現在のVLMはテキストのみの文書では高い性能を発揮するものの、画像化された文書や、テキストと画像が混在する情報では性能が大幅に低下することが明らかになりました。これは、VLMの長文・マルチモーダル文書理解能力における今後の研究課題を示唆しています。