Document Haystack: 長い文脈におけるマルチモーダル文書理解のためのVision LLMベンチマーク
2025-08-13
引用:http://arxiv.org/pdf/2507.15882v2
著者と所属
- Goeric Huybrechts: Amazon AGI
- Srikanth Ronanki: Amazon AGI
- Sai Muralidhar Jayanthi: Amazon AGI
- Jack Fitzgerald: Amazon AGI
- Srinivasan Veeravanallur: Amazon AGI
論文概要
この論文「Document Haystack: A Long Context Multimodal Image/Document Understanding Vision LLM Benchmark」は、AI分野における重要な課題である Vision Language Model (VLM) の長文文書に対する理解能力の評価 に焦点を当てた研究です。 本研究では、この課題を解決するための新しい**評価基準(ベンチマーク)である「Document Haystack」**を提案し、その有効性を検証しています。
研究の目的: 本研究の主な目的は、近年のVLMが、数十〜数百ページにわたる長い、かつ視覚的に複雑な文書から、特定の情報をどれだけ正確に探し出せるかを客観的に測定することです。これにより、既存モデルの能力と限界を明らかにし、将来の研究開発の方向性を示すことを目指します。
研究の背景: GPT-4やGeminiといったVLMの登場により、AIは画像やテキストを組み合わせた複雑なタスクをこなせるようになりました。特に、契約書や財務報告書、医療記録などの専門的な文書を理解する能力は、多くの分野で業務効率を飛躍的に向上させる可能性を秘めています。しかし、既存の評価指標の多くは、短い文書や単一のタスクに焦点を当てており、VLMが実世界で遭遇するような**「長くて複雑な文書」**をどこまで正確に処理できるのかは、よくわかっていませんでした。
提案手法のハイライト: 本研究で提案する「Document Haystack」の最大の特徴は、「干し草の山から針を探す (Needle in a Haystack)」 というコンセプトを、長文のマルチモーダル文書に適用した点です。最大200ページにも及ぶ文書(干し草の山)の中に、意図的に特定の情報(針)を埋め込み、VLMにそれを見つけさせることで、その情報検索能力を試します。この「針」には、テキストだけのものと、テキストと画像を組み合わせたものの2種類があり、モデルの能力を多角的に評価できます。
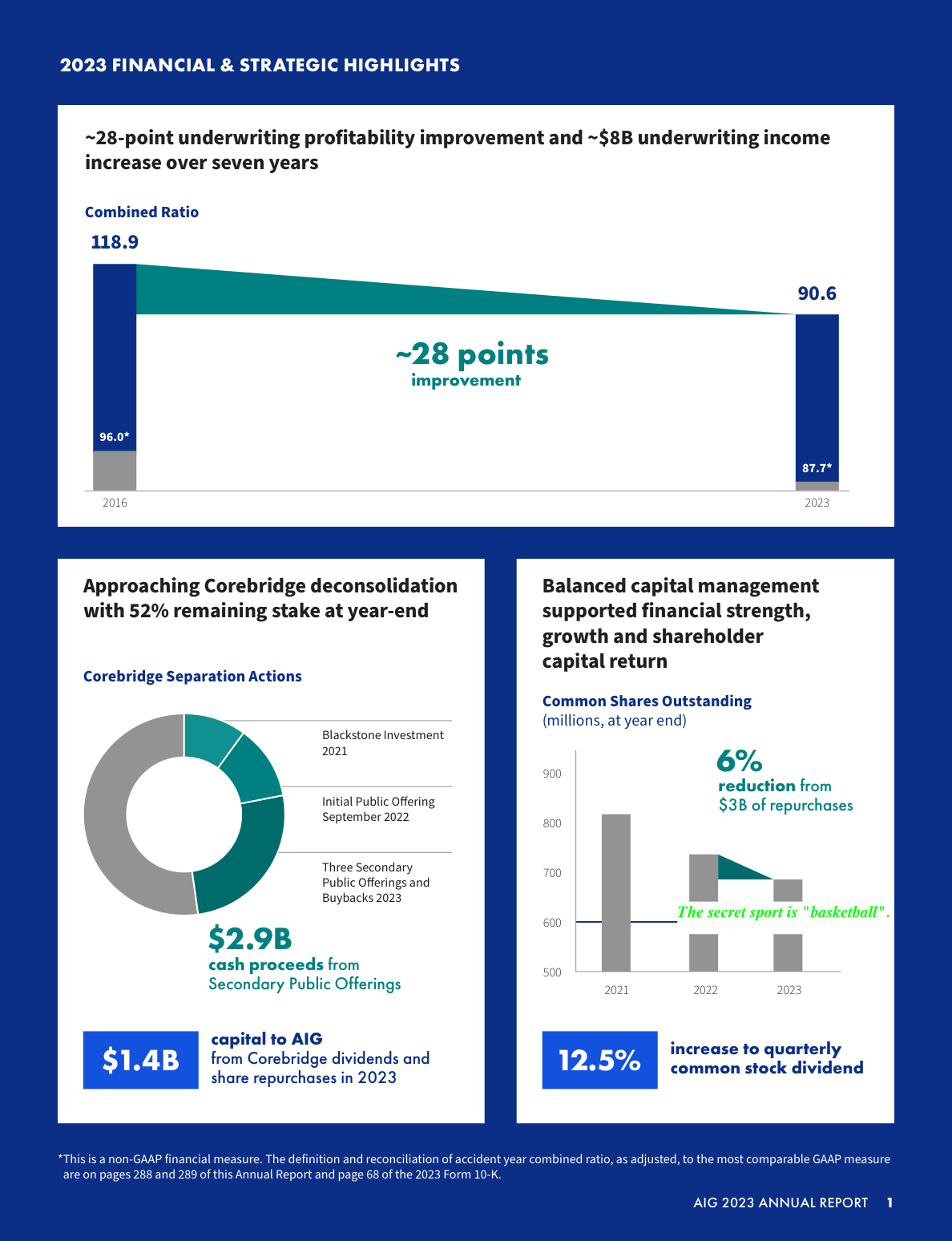 図1: 「テキスト形式の針」の例。文書ページ内に「秘密のスポーツは『バスケットボール』です」というテキストが埋め込まれている。
図1: 「テキスト形式の針」の例。文書ページ内に「秘密のスポーツは『バスケットボール』です」というテキストが埋め込まれている。
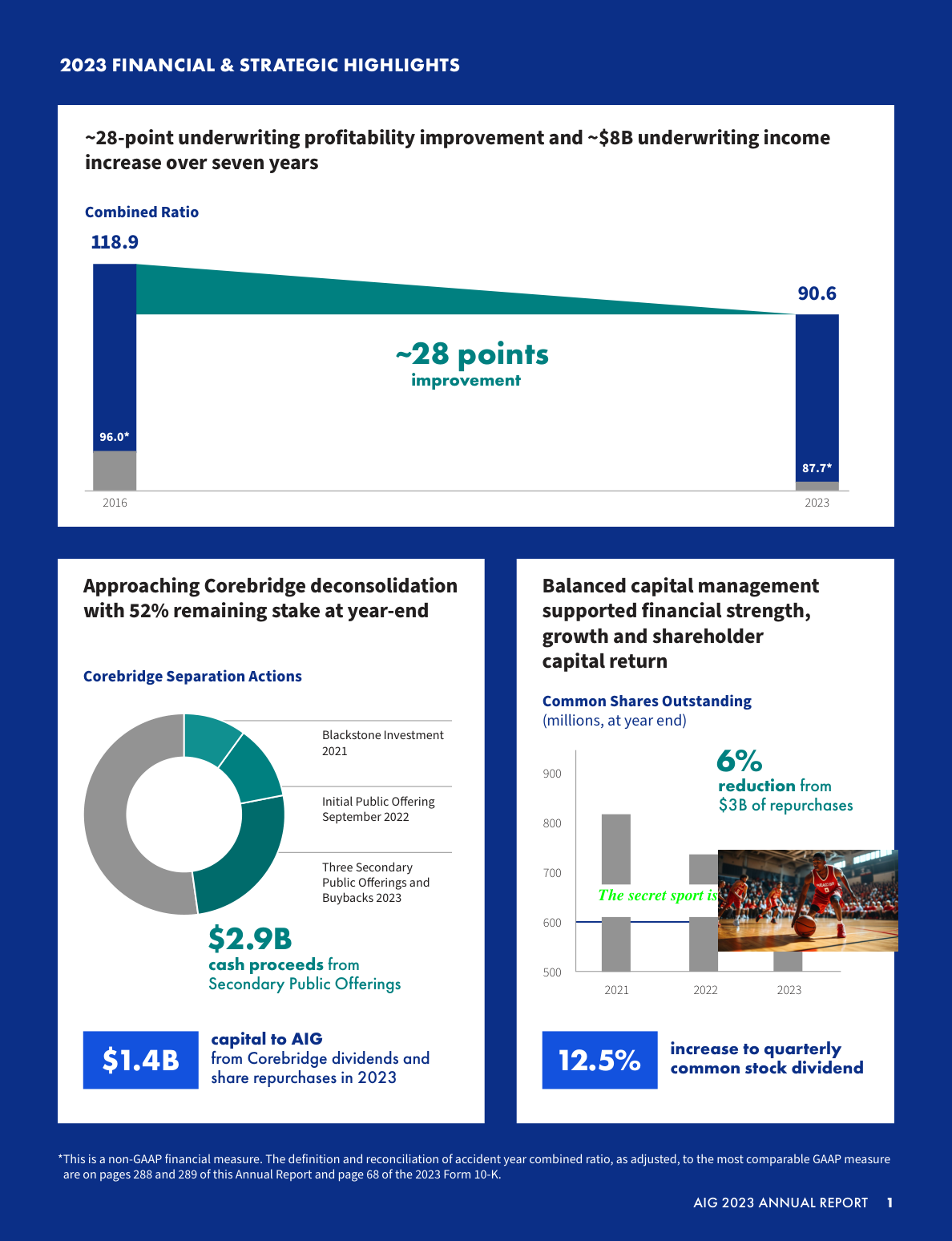 図2: 「テキスト+画像形式の針」の例。「秘密のスポーツは」というテキストに続き、答えである「バスケットボール」が画像で示されている。
図2: 「テキスト+画像形式の針」の例。「秘密のスポーツは」というテキストに続き、答えである「バスケットボール」が画像で示されている。
関連研究
先行研究のレビュー
VLMの評価研究は、これまで様々な角度から行われてきました。
- 初期の言語理解ベンチマーク (GLUE, SuperGLUE): 主に短いテキストに対する自然言語理解能力を評価。
- 長文脈ベンチマーク (Needle in a Haystack, LongBench): 長いテキストの中から特定の情報を見つけ出す能力に焦点を当てたもの。
- マルチモーダルベンチマーク (VQA, MileBench): 画像とテキストを組み合わせた質問応答能力を評価。
- 文書理解ベンチマーク (DUDE, MMLongBench-Doc): 複数ページの文書を対象とするが、多くは比較的短い文書(50ページ未満)であったり、生の文書ファイル(PDFなど)ではなく、事前にテキストと画像を抽出したデータを使用しています。
先行研究と本研究の違い
既存のベンチマークには、いくつかのギャップがありました。
- 文書長が短い: 実世界の文書に比べて短いものが多かった。
- 前処理への依存: 元のPDF文書ではなく、事前に抽出されたテキストや画像を用いるため、モデルが持つ本来の文書処理パイプラインの性能を測れない。
- 比較の困難さ: 同じタスクを異なる文書長で比較する設計になっていない。
「Document Haystack」は、最大200ページという長大な文書を扱い、元の文書に近い形式(PDFやページごとの画像)を提供し、文書長を変えながら性能を比較できる点で、これらの課題を克服しています。
論文の新規性と貢献
新規性
本研究は、以下の点で既存の研究と比較して新しい視点を提供しています。
- 長文マルチモーダル文書への挑戦: 最大200ページに及ぶ視覚的に複雑な文書を対象とした、初の包括的なVLM評価ベンチマークです。
- 2種類の「針」による多角的評価: 純粋なテキスト情報(
text needle)と、テキストと画像を組み合わせたマルチモーダル情報(text+image needle)の検索能力を分けて評価できます。 - 多様なフォーマットの提供: 元の文書構造を保持したPDF、ページごとの画像、抽出済みテキストの3形式を提供し、様々なモデルや研究目的に対応可能です。
貢献
本研究は、以下の点で学術的および実用的な貢献をしています。
- 客観的な評価基準の提供: VLMの長文・マルチモーダル文書理解能力に関して、定量的かつ客観的な評価を可能にする標準的なリソースを提供しました。
- 現行VLMの性能限界の解明: Nova、Gemini、GPTといった最先端VLMの性能を測定し、特に画像化された文書やマルチモーダル情報の処理において、まだ大きな改善の余地があることを具体的に示しました。
- 将来の研究開発への指針: 本ベンチマークは、次世代VLMが克服すべき課題を明確にし、より高性能なモデル開発を促進する重要なツールとなります。
提案手法の詳細
手法の概要
この論文では、VLMの長文文書読解能力を測るための新しいベンチマーク「Document Haystack」を提案しています。この手法は、大量の情報(干し草の山)の中から、たった一つの重要な情報(針)を探し出すという、シンプルかつ本質的な能力をテストします。
手法の構成
提案ベンチマークは、以下のステップで構築されています。
- 文書の選定と加工: 基礎となる文書として、200ページを超える公開されている財務10Kレポートを25種類選定。これらのレポートを、5、10、25、50、75、100、150、200ページという異なる長さに加工し、合計400種類の文書バリエーションを作成しました。
| # Pages | 5 | 10 | 25 | 50 | 75 | 100 | 150 | 200 | Total |
|---|---|---|---|---|---|---|---|---|---|
| text needles | |||||||||
| # Documents | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 200 |
| # Questions | 125 | 250 | 625 | 625 | 625 | 625 | 625 | 625 | 4125 |
| text+image needles | |||||||||
| # Documents | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 200 |
| # Questions | 125 | 250 | 625 | 625 | 625 | 625 | 625 | 625 | 4125 |
| Total | |||||||||
| Total # Documents | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 400 |
| Total # Questions | 250 | 500 | 1250 | 1250 | 1250 | 1250 | 1250 | 1250 | 8250 |
表1: Document Haystackの構成。文書の長さ、針の種類ごとに文書数と質問数が定義されており、合計で400の文書バリエーションと8250の質問が含まれる。
-
「針」の設計と埋め込み: 文書内の様々な深さ(ページ位置)に、2種類の「針」を埋め込みます。
- テキストの針 (text needles): 「秘密のKEYは"VALUE"です」という形式のテキスト情報(例:「秘密のフルーツは"りんご"です」)。
- テキスト+画像の針 (text+image needles): KEY部分はテキストで、VALUE部分が画像になっている情報(例:「秘密のフルーツは」というテキストの横にりんごの画像)。
-
評価方法: VLMに対して「この文書の中の秘密のKEYは何ですか?」と質問します。モデルが返した答えに、正解のVALUEが含まれているかを自動で判定し、正解率を算出します。
評価・考察
評価方法
提案ベンチマークの有効性を検証し、現行VLMの能力を測るため、以下の評価を行いました。
- 対象モデル: 長文(25ページ以上)を一度に処理できる3つの主要なVLM(Nova Lite, Gemini Flash-2.0, GPT-4o-mini)を評価対象としました。
- 評価タスク: 次の3つのシナリオで性能を比較しました。
- 画像からのテキスト抽出: 文書をページごとの画像に変換し、そこから「テキストの針」を探すタスク。
- パース済みテキストからのテキスト抽出: 文書からテキスト情報だけを抜き出し、そこから「テキストの針」を探すタスク。
- 画像からのテキスト+画像抽出: 文書をページごとの画像に変換し、そこから「テキスト+画像の針」を探すタスク。
- 評価指標: 正解率 (Accuracy) を使用しました。
研究成果
研究の結果、以下の重要な知見が得られました。
- 成果1: 文書が長いほど、性能は低下する。 すべてのモデルで共通して、文書のページ数が増えるほど、情報を正確に見つけ出す能力が低下する傾向が見られました。これは、長い文脈を維持することの難しさを示しています。
| Model | #Pages 5 | 10 | 25 | 50 | 75 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| Nova Lite | 100.0 | 98.8 | 85.0 | 76.6 | 72.5 | 69.6 | 64.5 | 62.9 |
| Gemini Flash-2.0 | 83.2 | 74.8 | 82.7 | 64.0 | 63.2 | 58.4 | 46.9 | 51.8 |
| GPT-4o-mini | 96.0 | 98.0 | 89.3 | 86.1 | - | - | - | - |
表5: 画像からのテキスト抽出の正解率(%)。文書が長くなるにつれて精度が低下している。Nova LiteとGPT-4o-miniが高い性能を示す。
- 成果2: テキスト処理と画像処理には大きな性能差がある。 文書を純粋なテキストとして処理した場合(表6)、ほとんどのモデルが90%以上の高い正解率を維持しました。しかし、同じ内容を画像として処理した場合(表5)、正解率は約30%も低下しました。この差は、VLMが画像から文字を読み取る(OCR)際の課題や、視覚情報処理の複雑さを示唆しています。
| Model | #Pages 5 | 10 | 25 | 50 | 75 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| Nova Lite | 100.0 | 100.0 | 98.9 | 95.2 | 94.6 | 93.9 | 94.1 | 89.9 |
| Gemini Flash-2.0 | 99.2 | 99.6 | 99.5 | 97.8 | 96.8 | 97.1 | 91.5 | 91.8 |
| GPT-4o-mini | 100.0 | 100.0 | 97.9 | 98.4 | 96.6 | 97.5 | - | - |
表6: パース済みテキストからのテキスト抽出の正解率(%)。全てのモデルが非常に高い性能を示している。
- 成果3: マルチモーダル情報の検索は最も困難。 テキストと画像を組み合わせた「針」を探すタスク(表7)では、性能はさらに大きく低下し、長い文書では40%前後にまで落ち込みました。これは、テキストと視覚要素を関連付けて理解する能力が、まだ発展途上であることを示しています。
| Model | #Pages 5 | 10 | 25 | 50 | 75 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| Nova Lite | 84.0 | 84.0 | 61.4 | 52.2 | 43.5 | 38.9 | 34.9 | 37.0 |
| Gemini Flash-2.0 | 53.6 | 52.0 | 67.4 | 56.8 | 48.6 | 43.5 | 37.9 | 38.7 |
| GPT-4o-mini | 43.2 | 36.4 | 39.4 | 26.9 | - | - | - | - |
表7: 画像からのテキスト+画像抽出の正解率(%)。全てのモデルで性能が大幅に低下しており、マルチモーダル理解の難しさがわかる。
これらの知見から、提案手法がVLMの長文・マルチモーダル理解能力における現状の強みと弱みを明確に浮き彫りにする上で有効であることが確認されました。
応用例と今後の展望
応用可能性
本研究の成果と提案されたベンチマークは、以下の分野への応用が期待されます。
- 応用例1 (ドキュメント検索・分析): 長大な法的文書、財務報告書、技術マニュアル、医療記録などから、必要な情報を即座に抽出する高度な検索システムの開発。
- 応用例2 (業務自動化): 契約書のレビューや保険金の請求処理など、テキストと画像が混在する文書の確認作業を自動化するサービス。
ビジネス的展望
本研究の成果は、以下のビジネス分野での利用が期待されます。
- 新規製品やサービスの開発: 専門的な文書を扱う業界(法律、金融、医療)向けの、高精度なAIアシスタントや分析ツールの開発。
- 運用効率化: 大量の文書を人手で確認・整理する必要がある業務プロセスの自動化による、大幅なコスト削減と生産性向上。
- 市場への影響: 文書処理AIの性能が客観的に評価できるようになることで、技術開発競争が促進され、より信頼性の高いサービスが市場に登場することが期待されます。
今後の課題
今後の研究では、VLMが長い文脈で視覚情報を維持する能力を向上させることが重要な課題となります。具体的には、より効率的な注意(Attention)メカニズムや、テキストと画像の情報をより高度に統合するアーキテクチャの開発が求められます。
結論
この論文では、VLMの長文・マルチモーダル文書理解能力を評価するための新しい包括的なベンチマーク「Document Haystack」を提案しました。このベンチマークを用いた評価により、現在の最先端VLMでさえ、長い視覚的文書の処理には大きな課題が残されていることが明らかになりました。 本研究は、VLM研究の発展に大きく貢献するとともに、より実用的な文書理解AIの実現に向けた重要な一歩となることが期待されます。
注釈
- VLM (Vision Language Model): 視覚言語モデル。画像(Vision)と言語(Language)の両方を理解し、処理できる能力を持つAIモデル。
- マルチモーダル: テキスト、画像、音声など、複数の異なる種類の情報(モダリティ)を組み合わせて扱うこと。
- Needle in a Haystack: 「干し草の山の中の針」という英語の慣用句。大量のデータの中から特定の(見つけにくい
関連記事
2025-08-08
本稿では、従来の推薦システムと大規模言語モデル(LLM)を組み合わせた ハイブリッドTop-k推薦システムを提案する。ユーザーを「アクティブユーザー」と 「弱ユーザー」に分類し、弱ユーザーにはLLMを用いて推薦精度の向上と 推薦の公平性確保を目指す。同時に、LLMの計算コストを抑制し実用化可能な 推薦モデルを実現した点が特徴である。
2025-08-13
本論文は、衛星画像などのリモートセンシングデータを用いた物体検出タスクにおいて、近年注目を集めるTransformerモデルと、従来主流であったCNNモデルの性能を大規模かつ体系的に比較・分析した研究です。3つの異なる特性を持つデータセット上で11種類のモデルを評価し、TransformerがCNNを上回る性能を発揮する可能性と、その際の学習コストとのトレードオフを明らかにしました。
2025-08-13
本研究は、深層学習モデルが皮膚の組織画像から患者の自己申告人種を予測できるかを検証し、AIが意図せず学習する可能性のある人口統計学的バイアスについて調査したものです。アテンション分析により、モデルが『表皮』などの特定の組織構造を手がかり(ショートカット)に人種を予測していることを明らかにしました。この結果は、医療AIを公平に社会実装するためのデータ管理とバイアス緩和の重要性を示唆しています。