効率的かつ責任ある大規模言語モデルの適応による、堅牢で公平なTop-k推薦
2025-08-08
著者と所属
- Kirandeep Kaur(ワシントン大学・アメリカ)
- Manya Chadha(ワシントン大学・アメリカ)
- Vinayak Gupta(ワシントン大学・アメリカ)
- Chirag Shah(ワシントン大学・アメリカ)
論文概要
本論文Efficient and Responsible Adaptation of Large Language Models for Robust and Equitable Top-k Recommendationsでは、推薦システム分野における2つの重要課題に同時に取り組んでいます。
- データの偏りによる推薦の不公平性
- 大規模言語モデル(LLM)の高コスト運用
従来の推薦システムは全ユーザーに一律の手法を適用しますが、その結果、利用頻度の低いユーザーや少数派属性のユーザーへの精度が低下する傾向があります。
一方、LLMを用いる推薦システムは高精度が期待されるものの、計算・運用コストが膨大になるという課題があります。
本研究では、これらの課題を解決するために、従来手法とLLMを組み合わせたハイブリッド推薦システムを提案。
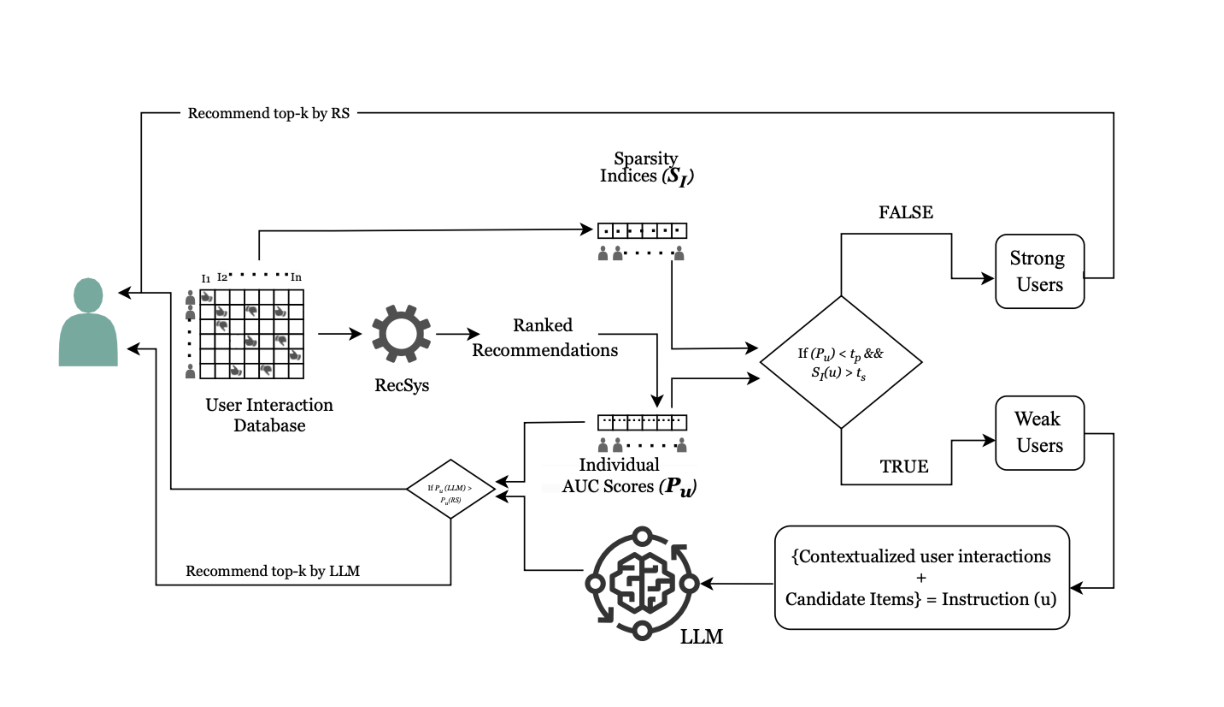
まず従来システムでユーザーを**「アクティブユーザー」と「弱ユーザー」**に分類し、アクティブユーザーには従来手法、弱ユーザーにはLLMを適用することで、コストを抑えつつ公平性を高めた推薦を実現しています。
研究目的
- データ偏りによる推薦の不公平性を緩和
- LLM活用時の計算・運用コストの削減
研究背景
推薦システムはECサイト、動画配信、音楽配信など多様なサービスで重要な役割を果たしています。
行動履歴の蓄積によって精度は向上していますが、一方で推薦の偏りが問題視されています。特定商品ばかり推薦されることで、ユーザーが新しい選択肢に触れる機会が減少し、多様性が損なわれる懸念があります。
また、近年はChatGPTに代表されるLLMが注目を集めています。LLMは自然言語理解を活かして高度な推薦が可能ですが、従来手法に比べて計算資源とコストの負担が大きい点が実用化の壁となっていました。
提案手法のハイライト
- 従来の推薦システムとLLMを組み合わせたハイブリッド構成
- ユーザー分類
- アクティブユーザー:頻繁に利用・購入するユーザー → 従来手法で推薦
- 弱ユーザー:利用頻度やデータ量が少ないユーザー → LLMで推薦
- LLM利用を必要最小限に抑え、「弱ユーザー」の推薦精度を向上
関連研究
先行研究のレビュー
- 推薦システムにおける公平性:特定属性のユーザーやアイテムに偏らない推薦手法の提案
- LLMを用いた推薦:レビューや説明文を解析し、自然言語による高度な推薦を実現
本研究の位置付け
従来は公平性問題とLLMの高コスト問題を別々に扱っていました。本研究は両者を同時に解決するアプローチを提示しています。
論文の新規性と貢献
新規性
- 「弱ユーザー」概念の導入
属性ではなくデータ量を基準に分類 - ハイブリッド推薦システム
アクティブユーザーには従来手法、弱ユーザーにはLLMを適用し、公平性とコスト効率を両立
貢献
- 公平性向上:従来手法では精度が低い弱ユーザーにも適切な推薦が可能
- 実用化促進:LLM利用範囲を限定することで、計算・運用コストを削減
提案手法の詳細
ステップ1. ユーザー分類
- 活動履歴を基に**AUC(Area Under the Curve)**を算出
- AUCが低いユーザー → 弱ユーザー
AUCが高いユーザー → アクティブユーザー
ステップ2. 推薦手法の適用
- 弱ユーザー → LLM(GPT-4、Claude 3.5-haiku、LLaMA 3-70B-Instruct)で推薦
- アクティブユーザー → 従来手法で推薦
全体構成
- データ前処理(ユーザーID、アイテムID、評価値抽出)
- 8種の推薦モデル(ItemKNN, NeuMF, DMF, NNCF, BPR, BERT4Rec, GRU4Rec, SASRec)を学習
- AUCに基づきユーザー分類
- 弱ユーザーにLLM推薦を適用
評価と考察
実験設定
- データセット:MovieLens 1M、Amazon Software、Amazon Video Games
- 指標:NDCG@10(上位10件の関連性を評価)
- 従来手法 vs 提案手法(LLM適用)
結果
- 全データセットで精度向上
- 特に弱ユーザーにおける精度改善が顕著
- LLM利用を限定することでコスト削減も実現
(※詳細な数値比較は原文表を参照)
応用例と今後の展望
応用可能性
- 教育:学習進度に応じた教材推薦
- 就職支援:スキルや経歴に合った求人推薦
- 医療:症状や検査結果に基づく治療法推薦
ビジネス的効果
- 顧客満足度向上
- 新規顧客獲得支援
- 運用コスト削減
今後の課題
- 弱ユーザー定義の精緻化
- LLM推薦の説明性向上
結論
本研究は、従来手法とLLMを組み合わせることで、公平性と効率性を両立した推薦システムを実現しました。
弱ユーザーへの精度向上とコスト削減を同時に達成し、今後の推薦システム研究と実用化において重要な一歩となることが期待されます。
関連記事
2025-08-08
本論文は、大規模言語モデル(LLM)における長文コンテキスト処理の効率性と性能向上を目的とし、クエリに基づいて動的に情報を補完する「クエリガイド型アクティベーションリフィル(ACRE)」手法を提案する。二層KVキャッシュとクエリガイド型リフィルを組み合わせることで、ネイティブのコンテキストウィンドウを超える長文処理を可能にし、ロングコンテキスト情報検索の実用性を大きく高めた。
2025-08-08
本論文では、コードレビューにおける修正に繋がる望ましいレビューコメント(DRC)を自動的に識別する新手法「Desiview」を提案します。Desiviewにより高品質なデータセットを構築し、LLaMAモデルをファインチューニングおよびアラインメントすることで、DRC生成能力が大幅に向上したことを実証しました。本手法はコードレビュー自動化やソフトウェア開発支援に大きく貢献することが期待されます。
2025-08-13
本論文では、最大200ページに及ぶ長い文書から特定の情報を探し出す能力を測定する新しいベンチマーク「Document Haystack」を提案します。このベンチマークは、文書内に意図的に埋め込まれたテキスト情報や画像情報(「針」)を、Vision Language Model(VLM)がどれだけ正確に見つけ出せるかを評価します。実験の結果、現在のVLMはテキストのみの文書では高い性能を発揮するものの、画像化された文書や、テキストと画像が混在する情報では性能が大幅に低下することが明らかになりました。これは、VLMの長文・マルチモーダル文書理解能力における今後の研究課題を示唆しています。