VisionThink: 強化学習で実現する賢く効率的な視覚言語モデル
2025-08-15
引用:http://arxiv.org/pdf/2507.13348v1
著者と所属
- Senqiao Yang: CUHK
- Junyi Li: HKU
- Xin Lai: CUHK
- Bei Yu: CUHK
- Hengshuang Zhao: HKU
- Jiaya Jia: CUHK, HKUST
( CUHK: 香港中文大学, HKU: 香港大学, HKUST: 香港科技大学 )
論文概要
この論文「VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning」は、視覚言語モデル(VLM)の分野における重要な課題である 「性能向上に伴う計算コストの爆発的な増加」 に焦点を当てた研究です。 本研究では、この課題を解決するために、タスクの難易度に応じて動的に画像の解像度を切り替える新しいパラダイム 「VisionThink」 を提案し、その有効性を検証しています。
研究の目的: 本研究の主な目的は、VLMが高い性能を維持しながら、計算コスト(特に視覚トークン数)を大幅に削減することです。これを、モデルが人間のように「まずはざっと見て、必要なら詳しく見る」という判断を自律的に行うことで実現します。
研究の背景: 近年、VLMは目覚ましい性能向上を遂げていますが、その代償として入力画像の解像度を上げ、処理する「視覚トークン」の数を大幅に増やしてきました。これにより、膨大な計算リソースが必要となり、実世界での応用を妨げる一因となっています。 しかし、研究チームは「すべてのタスクで高解像度画像が必要なわけではない」という点に着目しました。一般的な画像に関する質問応答(VQA)では低解像度でも十分に答えられますが、画像内の文字を読み取るOCRタスクなど、ごく一部のタスクでは高解像度が不可欠です。既存の効率化手法は、一律の圧縮率を適用するため、こうしたOCRタスクで性能が大きく低下するという問題がありました。
提案手法のハイライト: 本研究で提案する「VisionThink」の最も重要な特徴は、強化学習(RL)を用いて、モデル自身が「低解像度で十分か、高解像度が必要か」を判断する能力を獲得する点です。 まず低解像度の画像で処理を開始し、情報が不十分だと判断した場合にのみ、モデルは特別なトークンを出力して高解像度画像を要求します。この賢い判断により、簡単なタスクでは計算量を大幅に節約し、難しいタスクでは性能を妥協しない、という理想的な動作を可能にしました。
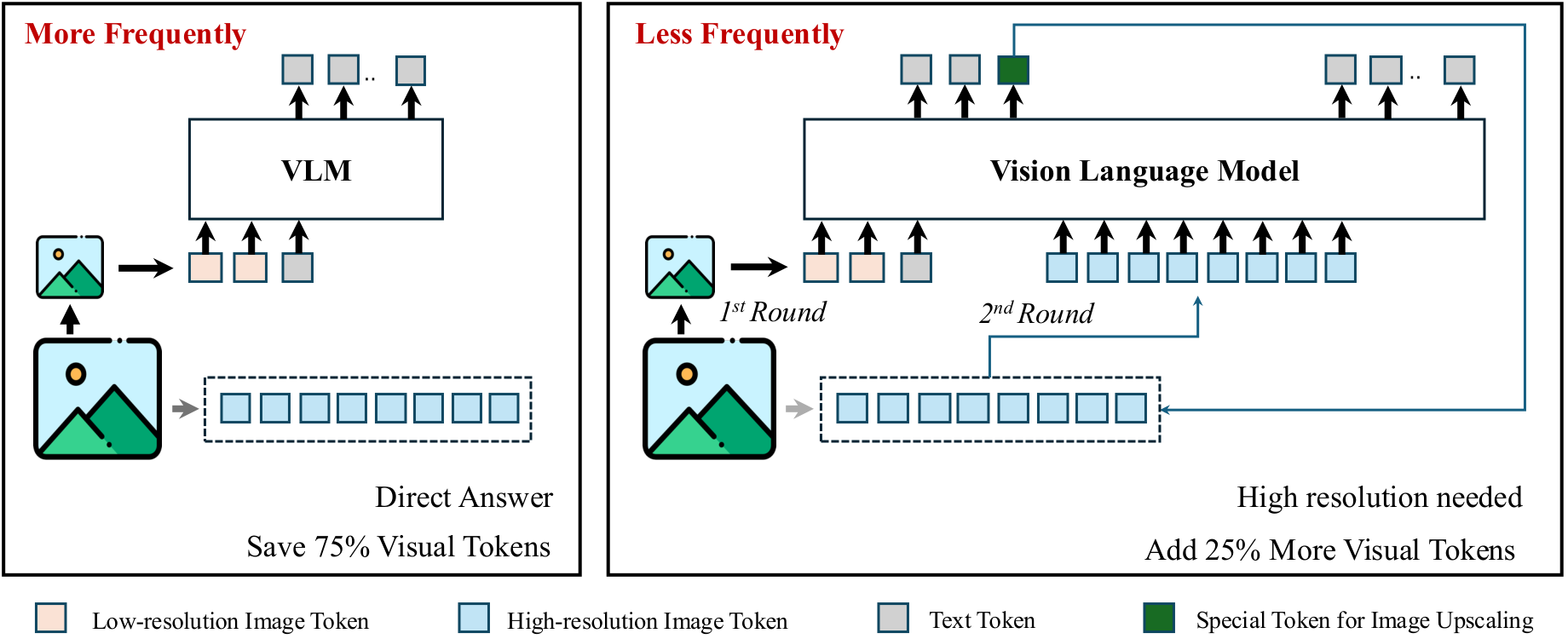 図1: VisionThinkのフレームワーク。(a) 簡単なタスクでは、解像度を1/4に下げた画像から直接答えを生成します。(b) 難しいタスクでは、モデルが情報不足を検知し、高解像度の画像を要求してから答えを生成します。
図1: VisionThinkのフレームワーク。(a) 簡単なタスクでは、解像度を1/4に下げた画像から直接答えを生成します。(b) 難しいタスクでは、モデルが情報不足を検知し、高解像度の画像を要求してから答えを生成します。
関連研究
先行研究のレビュー
- VLMの効率化研究: 多くの研究がVLMの視覚トークンの冗長性に注目し、トークンを枝刈り(プルーニング)したり、統合したりする手法を提案してきました。しかし、これらの手法はほとんどが「固定の比率」や「固定のしきい値」を用いており、タスクの内容によらず一律にトークンを削減するため、詳細な情報が必要なタスクでの性能低下が課題でした。
- VLMにおける強化学習: 強化学習は言語モデルの推論能力向上などで成果を上げていますが、VLMへの応用は限定的でした。特に、答えが多様で自由な形式になりがちな一般的なVQAタスクでは、どの回答が良いかをルールベースで評価するのが難しく、強化学習の適用が困難でした。
先行研究と本研究の違い
本研究は、先行研究とは異なり、効率化を「サンプルレベル」で動的に行うという新しい視点を提示しています。トークンを後から捨てるのではなく、最初から圧縮された情報(低解像度画像)を与え、モデルの「思考」に基づいて追加情報を要求させるアプローチは、より人間らしい効率的な情報処理と言えます。また、一般的なVQAタスクに強化学習を適用するための「LLM-as-Judge」戦略も、本研究の重要な独自性です。
論文の新規性と貢献
新規性
本研究は、以下の点で既存の研究と比較して新しい視点を提供しています。
- 動的な解像度選択パラダイム: 画像を一律に処理するのではなく、タスクの要求に応じてモデルが自律的に解像度を選択する、賢く効率的な新しい処理パラダイムを提案しました。
- 一般VQAへの強化学習適用手法「LLM-as-Judge」: 答えの正しさをルールで定義しにくい一般的なVQAタスクにおいて、外部の高性能LLMを「審判」として利用することで、強化学習の適用を可能にしました。
- バランスの取れた報酬設計: モデルが「常に高解像度を要求する」または「常に低解像度で答える」といった極端な行動に陥らないよう、ペナルティを動的に調整する巧妙な報酬関数を設計しました。
貢献
本研究は、以下の点で学術的および実用的な貢献をしています。
- 性能と効率の両立: OCR関連タスクのような高い精度が求められる場面では性能を維持しつつ、他の多くのタスクで計算コストを大幅に削減できることを示し、VLMの実用性を高めました。
- 強化学習の新たな応用: VLMにおける強化学習の可能性を広げ、より複雑で一般的なタスクにも適用できる道筋を示しました。
- VLM研究への新しい視点: VLMをより賢く、人間のように振る舞わせるための新しい研究方向性(例:ツールの動的利用)を提示し、今後の研究を促進する可能性があります。
提案手法の詳細
手法の概要
この論文では、強化学習に基づく効率的なVLM「VisionThink」を提案しています。この手法は、以下の主要なアイデアに基づいています。
- 階層的な画像処理: まずは低コストな低解像度画像で処理を行い、必要に応じて高コストな高解像度画像を追加で要求する。
- 自律的な判断: 高解像度画像が必要かどうかの判断を、モデル自身が強化学習を通じて学習する。
手法の構成
提案手法は、以下の3つの主要な構成要素から成り立っています。
-
審判としてのLLM (LLM-as-Judge): 一般的なVQAタスクでは、モデルの生成した回答が正しいかどうかを自動で評価するのが困難です。例えば「この絵は美しいですか?」という質問には多様な正解がありえます。この問題を解決するため、本研究では外部の高性能なLLMを「審判」として利用します。審判LLMは、モデルの回答と正解(Ground Truth)をテキストのみで比較し、その正しさを「1(正解)」か「0(不正解)」のスコアで評価します。これにより、多様な回答形式に対応可能な、客観的で柔軟な評価が実現されます。
-
マルチターン強化学習 (Multi-Turn GRPO): VisionThinkの処理フローは「①低解像度で回答を試みる→②高解像度を要求する→③高解像度で回答する」という複数のステップ(ターン)から構成されることがあります。この一連の対話的なプロセスを学習させるため、研究チームはGRPO(Group Relative Policy Optimization)という強化学習アルゴリズムをマルチターン設定に拡張しました。モデルが高解像度を要求する際には、特定のプロンプトに従って特別なトークン(関数呼び出し)を出力するように学習させます。
-
巧妙な報酬設計: モデルを賢く学習させるためには、良い行動に報酬を与え、悪い行動にペナルティを与える「報酬関数」の設計が非常に重要です。VisionThinkの報酬関数は、以下の3つの要素で構成されます。
式1: VisionThinkの全体的な報酬関数。正確性、フォーマット、ペナルティ制御の3つの要素から構成されます。
- 正確性報酬 (): LLM-as-Judgeが判断した回答の正しさに基づき与えられます(正解なら1、不正解なら0)。
- フォーマット報酬 (): モデルが指定された形式(思考過程を
<think>タグで囲むなど)を守った場合に与えられます。 - ペナルティ制御 (): これが本手法の鍵です。ペナルティを設けないと、モデルは性能を最大化するために常に高解像度画像を要求するようになってしまいます。逆に、常にペナルティを与えると、今度は常に低解像度で答えようとする極端な振る舞いに陥ります。
そこで、研究チームは**「低解像度で正解できる確率」**に基づいてペナルティを動的に与える方法を考案しました。
- 低解像度で正解しにくいタスクの場合 → 低解像度で直接答える行動にペナルティを与え、高解像度要求を促す。
- 低解像度で正解しやすいタスクの場合 → 高解像度を要求する行動にペナルティを与え、効率的な直接回答を促す。
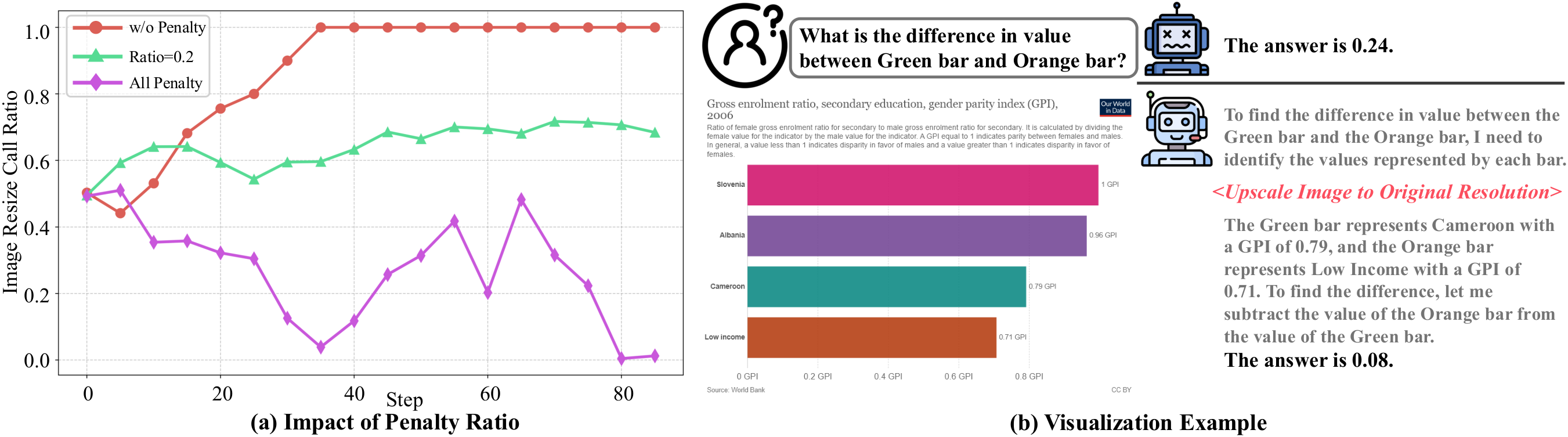 図2: ペナルティ比率の影響。ペナルティがない場合(青線)や、常にペナルティを課す場合(紫線)は、モデルの行動が極端(常に高解像度を要求するか、常に直接回答する)に陥ってしまいます。適切なペナルティ制御により、バランスの取れた挙動が実現されます(緑線が本手法)。
図2: ペナルティ比率の影響。ペナルティがない場合(青線)や、常にペナルティを課す場合(紫線)は、モデルの行動が極端(常に高解像度を要求するか、常に直接回答する)に陥ってしまいます。適切なペナルティ制御により、バランスの取れた挙動が実現されます(緑線が本手法)。
評価・考察
評価方法
提案手法の有効性を検証するために、多様なVQAベンチマークを用いて評価を行いました。
- 使用したベンチマーク:
- OCR関連: ChartQA, OCRBench(グラフや文書の文字読み取り能力を測る)
- 一般VQA: MME, MMVet, RealWorldQA, POPE(一般的な知覚・認知能力を測る)
- 数学推論: MathVista, MathVerse(図を含む数学の問題解決能力を測る)
- 比較対象:
- ベースモデル(Qwen2.5-VL-7B-Instruct)
- 他の効率化VLM(FastV, SparseVLM, VisionZip)
- 最先端のクローズドソースモデル(GPT-4oなど)
- 評価指標: 各ベンチマークのスコア、推論時間、高解像度画像の要求率
研究成果
-
成果1: 賢く、効率的であること VisionThinkは、タスクの性質に応じて高解像度画像を要求する割合を自律的に変化させることができました。下の図が示すように、OCR関連のChartQAやOCRBenchでは要求率が高い一方で、MMEやDocVQAのような一般的なタスクでは70%以上を低解像度のままで処理しており、賢く効率的に動作していることがわかります。
-
成果2: 高い性能を維持 下の表は、他の効率化VLMとの性能比較を示しています。既存手法(FastV, SparseVLM)は、トークンを削減するとChartQAやOCRBenchのようなOCRタスクで性能が大きく低下します。一方、VisionThinkは必要に応じて高解像度画像を利用するため、これらのタスクでも高い性能を維持しつつ、全体として高い平均スコアを達成しました。
Method ChartQA† OCRBench DocVQA MME MMVet RealWorldQA POPE MathVista MathVerse Avg. Vanilla 79.8 81.4 95.1 2316 61.6 68.6 86.7 68.2 44.3 100% Down-Sample (1/4) 2.5 45.3 88.8 2277 45.4 64.6 84.7 45.8 32.4 74.3% VisionThink (Ours) 79.8 80.8 94.4 2400 67.1 68.5 86.0 66.8 48.0 102.0% SparseVLM 73.2 75.6 66.8 2282 51.5 68.4 85.5 66.6 45.1 92.2% FastV 72.6 75.8 93.6 2308 52.8 68.8 84.7 63.7 45.0 95.8% 表1: 既存の効率化VLMとの性能比較。VisionThinkは、全体の視覚トークンを60%未満に抑えながらも、ベースライン(Vanilla)を超える平均性能(102%)を達成しました。特にOCR関連タスク(ChartQA, OCRBench)での性能低下が少ない点が特徴です。
-
成果3: 推論の高速化 推論時間に関しても、VisionThinkは大きな利点を示しました。下の図は、常に高解像度で推論するモデル(Qwen-RL)や、常に1/4解像度で推論するモデル(Qwen-RL 1/4)との比較です。VisionThinkは、多くのタスクで1/4解像度モデルに近い推論速度を達成し、高解像度モデルよりも大幅に高速でした。
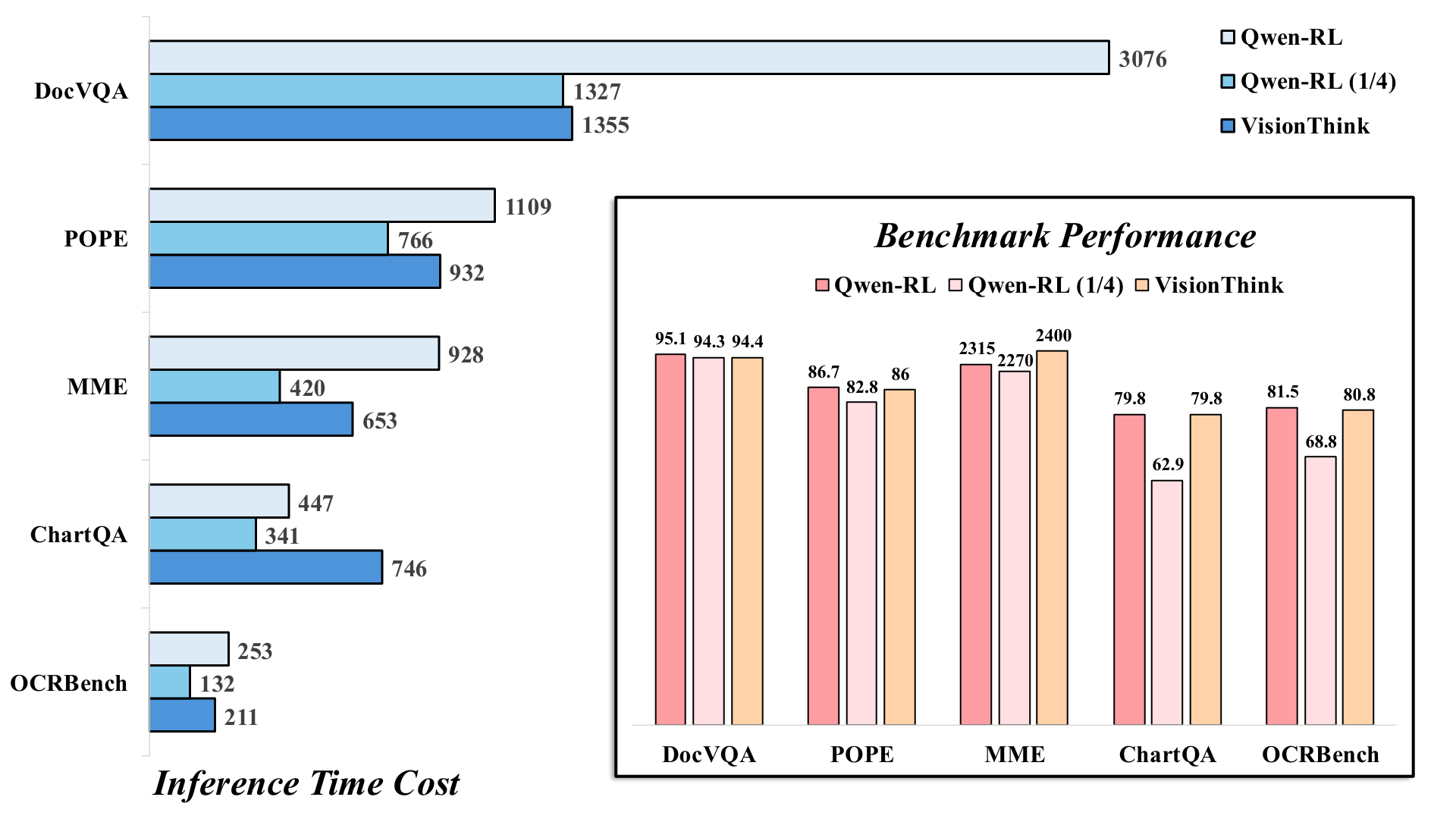 図4: 推論時間と性能の比較。青い棒が性能、オレンジの棒が推論時間を示します。VisionThinkは、1/4解像度モデルに近い速度で、高解像度モデルに匹敵する、あるいはそれ以上の性能を達成しています。
図4: 推論時間と性能の比較。青い棒が性能、オレンジの棒が推論時間を示します。VisionThinkは、1/4解像度モデルに近い速度で、高解像度モデルに匹敵する、あるいはそれ以上の性能を達成しています。
応用例と今後の展望
応用可能性
本研究の成果は、計算リソースが限られる環境でのVLMの活用を促進します。
- 応用例1: エッジデバイスでのAI: スマートフォンやスマートグラスなどのデバイス上で、高速かつ高性能な視覚アシスタントを実現できます。
- 応用例2: 自動運転・ロボティクス: 周囲の状況を素早く判断し、危険標識など詳細な確認が必要な場合にのみ処理を重くする、といった効率的なシステムを構築できます。
ビジネス的展望
本研究の成果は、VLMを用いたサービスのコストパフォーマンスを大幅に向上させる可能性があります。
- 運用効率化: VLMをサービスとして提供する際のサーバーコストを削減し、より多くのユーザーに低価格で提供できます。
- ユーザー体験の向上: 応答速度が向上するため、リアルタイム性が求められるアプリケーションでのユーザー体験が改善します。
今後の課題
本研究は大きな成果を上げましたが、まだ発展の余地があります。
- より柔軟な解像度選択: 現在は「低」と「高」の2段階ですが、タスクに応じて複数の解像度をより柔軟に使い分ける仕組みが考えられます。
- 他の視覚ツールの統合: 解像度変更だけでなく、「画像の特定領域を拡大する(クロップ)」といった他のツールを統合することで、さらに効率的で高性能なモデルが期待できます。
結論
この論文では、VLMの効率と性能を両立させる新しいパラダイム「VisionThink」を提案しました。強化学習を用いて、モデルがタスクの難易度に応じて自律的に画像の解像度を切り替えることで、簡単なタスクでは計算コストを大幅に削減し、複雑なタスクでは高い性能を維持することに成功しました。この「賢い」アプローチは、VLMの実用性を大きく向上させ、今後のAI研究開発に新たな方向性を示すものと言えます。
注釈
- 視覚言語モデル (VLM): Vision-Language Modelの略。画像(視覚情報)とテキスト(言語情報)の両方を理解し、処理することができるAIモデル。
- 強化学習 (RL): Reinforcement Learningの略。AI(エージェント)が環境内で試行錯誤を繰り返し、報酬を最大化するような行動(方策)を学習する機械学習の一手法。
- 視覚トークン: 画像をAIが処理しやすいように、小さなパッチ(断片)に分割したもの。トークン数が多いほど、より詳細な情報を扱えるが計算コストが増大する。
- OCR: Optical Character Recognition(光学的文字認識)の略。画像や文書に含まれる文字を認識し、テキストデータに変換する技術。
- VQA: Visual Question Answering(視覚的質問応答)の略。画像の内容に関する質問にAIが答えるタスク。
- LLM-as-Judge: 評価が難しいタスクにおいて、大規模言語モデル(LLM)を「審判」役として利用し、生成された出力の品質や正しさを評価させる手法。
- GRPO: Group Relative Policy Optimizationの略。強化学習アルゴリズムの一種で、複数の生成結果をグループとして比較し、より良い結果を生成しやすいように方策を更新する。
関連記事
2025-08-13
本論文は、衛星画像などのリモートセンシングデータを用いた物体検出タスクにおいて、近年注目を集めるTransformerモデルと、従来主流であったCNNモデルの性能を大規模かつ体系的に比較・分析した研究です。3つの異なる特性を持つデータセット上で11種類のモデルを評価し、TransformerがCNNを上回る性能を発揮する可能性と、その際の学習コストとのトレードオフを明らかにしました。
2025-08-13
本研究は、深層学習モデルが皮膚の組織画像から患者の自己申告人種を予測できるかを検証し、AIが意図せず学習する可能性のある人口統計学的バイアスについて調査したものです。アテンション分析により、モデルが『表皮』などの特定の組織構造を手がかり(ショートカット)に人種を予測していることを明らかにしました。この結果は、医療AIを公平に社会実装するためのデータ管理とバイアス緩和の重要性を示唆しています。
2025-08-13
本論文では、最大200ページに及ぶ長い文書から特定の情報を探し出す能力を測定する新しいベンチマーク「Document Haystack」を提案します。このベンチマークは、文書内に意図的に埋め込まれたテキスト情報や画像情報(「針」)を、Vision Language Model(VLM)がどれだけ正確に見つけ出せるかを評価します。実験の結果、現在のVLMはテキストのみの文書では高い性能を発揮するものの、画像化された文書や、テキストと画像が混在する情報では性能が大幅に低下することが明らかになりました。これは、VLMの長文・マルチモーダル文書理解能力における今後の研究課題を示唆しています。