VisionThink: Smart and Efficient Vision Language Models via Reinforcement Learning
2025-08-15
Citation: http://arxiv.org/pdf/2507.13348v1
Authors and Affiliations
- Senqiao Yang: CUHK
- Junyi Li: HKU
- Xin Lai: CUHK
- Bei Yu: CUHK
- Hengshuang Zhao: HKU
- Jiaya Jia: CUHK, HKUST
( CUHK: The Chinese University of Hong Kong, HKU: The University of Hong Kong, HKUST: The Hong Kong University of Science and Technology )
Paper Overview
This paper, "VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning," is a study focusing on a critical challenge in the field of Vision-Language Models (VLMs): the "explosive increase in computational cost that accompanies performance improvements." To solve this issue, this research proposes and validates a new paradigm called "VisionThink," which dynamically switches image resolution according to the task's difficulty.
Research Objective: The main objective of this study is to significantly reduce the computational cost (especially the number of visual tokens) of VLMs while maintaining high performance. This is achieved by enabling the model to autonomously make judgments, much like a human "skims first, then looks closer if necessary."
Research Background: In recent years, VLMs have achieved remarkable performance improvements, but at the cost of increasing the resolution of input images and substantially expanding the number of "visual tokens" to be processed. This has required vast computational resources, becoming a barrier to real-world applications. However, the research team noted that "not all tasks require high-resolution images." While general Visual Question Answering (VQA) can be adequately answered with low-resolution images, only a few tasks, such as OCR tasks that read text within images, indispensably require high resolution. Existing efficiency methods apply a uniform compression rate, which posed a problem of significant performance degradation in such OCR tasks.
Highlights of the Proposed Method: The most important feature of the "VisionThink" method proposed in this study is that it uses reinforcement learning (RL) to enable the model to acquire the ability to decide for itself whether "low resolution is sufficient or high resolution is needed." The process starts with a low-resolution image, and only if the model determines the information is insufficient, it outputs a special token to request a high-resolution image. This intelligent decision-making allows for ideal behavior: significantly saving computational load on simple tasks and not compromising performance on difficult ones.
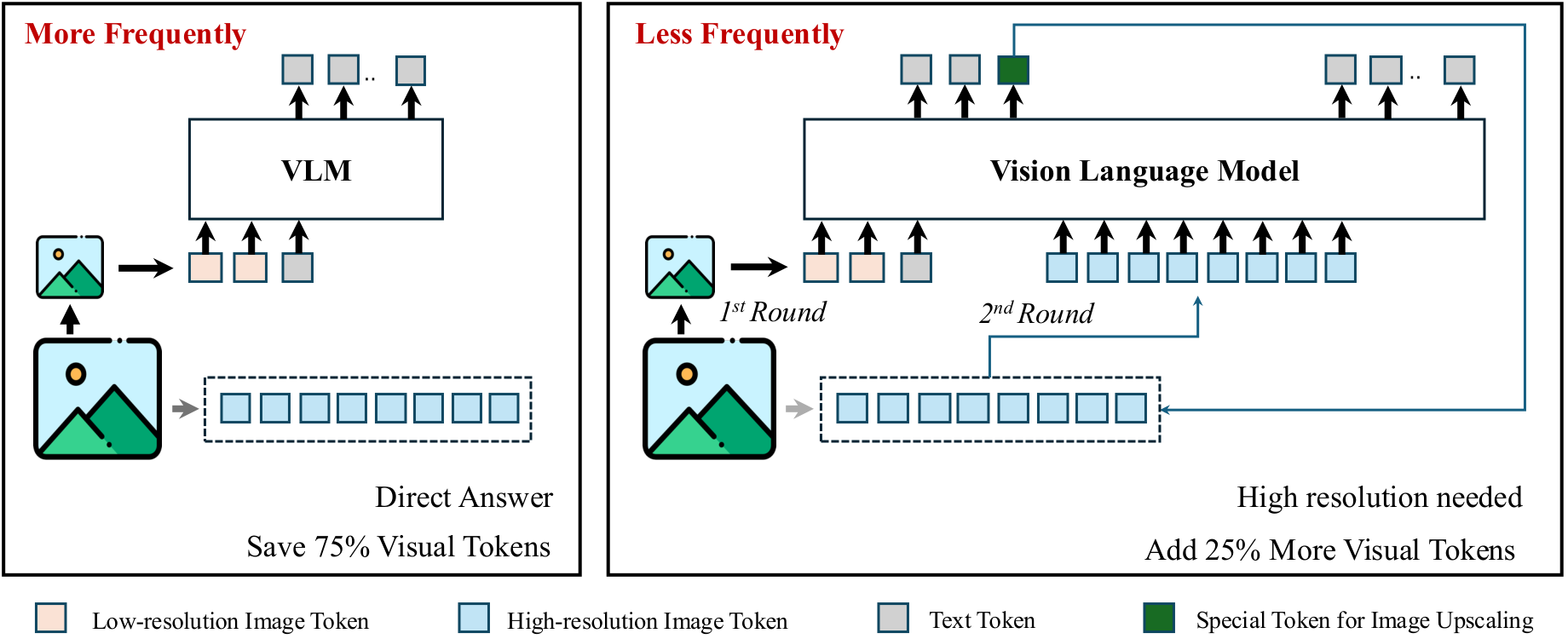 Figure 1: The VisionThink framework. (a) For simple tasks, it generates an answer directly from an image with its resolution reduced to 1/4. (b) For difficult tasks, the model detects a lack of information and requests a high-resolution image before generating an answer.
Figure 1: The VisionThink framework. (a) For simple tasks, it generates an answer directly from an image with its resolution reduced to 1/4. (b) For difficult tasks, the model detects a lack of information and requests a high-resolution image before generating an answer.
Related Work
Review of Prior Research
- VLM Efficiency Research: Many studies have focused on the redundancy of visual tokens in VLMs, proposing methods to prune or merge tokens. However, most of these methods used a "fixed ratio" or "fixed threshold," uniformly reducing tokens regardless of the task content, which led to performance degradation on tasks requiring detailed information.
- Reinforcement Learning in VLMs: While RL has shown success in improving the reasoning abilities of language models, its application to VLMs has been limited. Particularly for general VQA tasks where answers can be diverse and free-form, it has been difficult to apply RL because assessing the quality of an answer on a rule-based system is challenging.
Differences from Prior Research
This study presents a new perspective, differing from prior research by dynamically improving efficiency at the "sample level." Instead of discarding tokens later, the approach of providing compressed information (a low-resolution image) from the start and having the model request additional information based on its "thinking" is a more human-like and efficient information processing method. Furthermore, the "LLM-as-Judge" strategy for applying RL to general VQA tasks is another key originality of this research.
Novelty and Contributions
Novelty
This research offers new perspectives compared to existing studies in the following ways:
- Dynamic Resolution Selection Paradigm: Instead of processing images uniformly, it proposes a new smart and efficient processing paradigm where the model autonomously selects the resolution based on task requirements.
- "LLM-as-Judge" for General VQA Application: In general VQA tasks where it is difficult to define the correctness of an answer by rules, it enabled the application of reinforcement learning by using an external high-performance LLM as a "judge."
- Balanced Reward Design: It designed a sophisticated reward function with dynamically adjusted penalties to prevent the model from falling into extreme behaviors like "always requesting high resolution" or "always answering with low resolution."
Contributions
This research makes the following academic and practical contributions:
- Balancing Performance and Efficiency: It demonstrated that it is possible to maintain performance in situations requiring high accuracy, such as OCR-related tasks, while significantly reducing computational costs on many other tasks, thereby increasing the practicality of VLMs.
- New Application of Reinforcement Learning: It expanded the potential of RL in VLMs, showing a path for its application to more complex and general tasks.
- New Perspective for VLM Research: It presented a new research direction for making VLMs smarter and more human-like (e.g., dynamic use of tools), potentially stimulating future research.
Detailed Proposed Method
Method Overview
This paper proposes an efficient VLM based on reinforcement learning, "VisionThink." The method is based on the following key ideas:
- Hierarchical Image Processing: First, process with a low-cost, low-resolution image, and request a high-cost, high-resolution image only when necessary.
- Autonomous Judgment: The model learns to decide whether a high-resolution image is needed through reinforcement learning.
Components of the Method
The proposed method consists of the following three main components:
-
LLM-as-Judge: In general VQA tasks, it is difficult to automatically evaluate whether a model's generated answer is correct. For example, a question like "Is this painting beautiful?" can have various correct answers. To solve this problem, this research uses an external high-performance LLM as a "judge." The judge LLM compares the model's answer and the ground truth using only text and evaluates its correctness with a score of "1 (correct)" or "0 (incorrect)." This enables objective and flexible evaluation that can handle diverse answer formats.
-
Multi-Turn GRPO (Group Relative Policy Optimization): The VisionThink processing flow may consist of multiple steps (turns), such as "① attempt to answer with low resolution → ② request high resolution → ③ answer with high resolution." To learn this series of interactive processes, the research team extended the GRPO reinforcement learning algorithm to a multi-turn setting. The model is trained to output a special token (a function call) according to a specific prompt when requesting a high-resolution image.
-
Sophisticated Reward Design: To train the model intelligently, the design of the "reward function," which gives rewards for good actions and penalties for bad ones, is crucial. The VisionThink reward function consists of the following three elements:
Equation 1: The overall reward function for VisionThink. It is composed of three elements: accuracy, format, and penalty control.
- Accuracy Reward (): Given based on the correctness of the answer as determined by the LLM-as-Judge (1 for correct, 0 for incorrect).
- Format Reward (): Given when the model adheres to the specified format (e.g., enclosing the thought process in
<think>tags). - Penalty Control (): This is the key to this method. Without a penalty, the model would always request high-resolution images to maximize performance. Conversely, if a penalty is always applied, it falls into the extreme behavior of always trying to answer with low resolution.
Therefore, the research team devised a method to dynamically apply a penalty based on the "probability of being correct with low resolution."
- For a task that is difficult to answer correctly with low resolution → A penalty is given for answering directly with low resolution, encouraging a high-resolution request.
- For a task that is easy to answer correctly with low resolution → A penalty is given for requesting high resolution, encouraging an efficient direct answer.
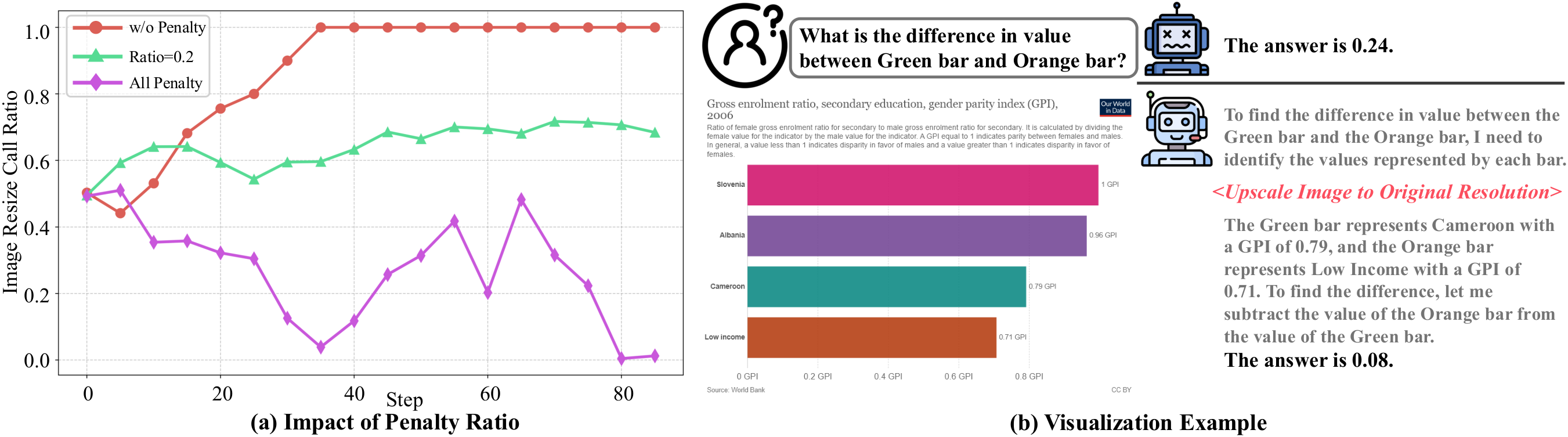
Figure 2: The impact of penalty ratios. Without a penalty (blue line) or when a penalty is always applied (purple line), the model's behavior becomes extreme (always requesting high resolution or always answering directly). Appropriate penalty control achieves a balanced behavior (green line is our method).
Evaluation and Discussion
Evaluation Method
To verify the effectiveness of the proposed method, it was evaluated using a variety of VQA benchmarks.
- Benchmarks Used:
- OCR-related: ChartQA, OCRBench (measuring the ability to read text in charts and documents)
- General VQA: MME, MMVet, RealWorldQA, POPE (measuring general perceptual and cognitive abilities)
- Math Reasoning: MathVista, MathVerse (measuring problem-solving ability in math problems involving diagrams)
- Comparison Targets:
- Baseline model (Qwen2.5-VL-7B-Instruct)
- Other efficient VLMs (FastV, SparseVLM, VisionZip)
- State-of-the-art closed-source models (e.g., GPT-4o)
- Evaluation Metrics: Scores on each benchmark, inference time, and high-resolution image request rate.
Research Results
-
Result 1: Smart and Efficient VisionThink was able to autonomously vary the rate at which it requested high-resolution images according to the nature of the task. As the figure below shows, while the request rate is high for OCR-related benchmarks like ChartQA and OCRBench, it processed over 70% of general tasks like MME and DocVQA with low resolution, demonstrating its smart and efficient operation.
-
Result 2: Maintains High Performance The table below shows a performance comparison with other efficient VLMs. Existing methods (FastV, SparseVLM) experience a significant performance drop on OCR tasks like ChartQA and OCRBench when tokens are reduced. In contrast, VisionThink utilizes high-resolution images when necessary, allowing it to maintain high performance on these tasks and achieve a high average score overall.
Method ChartQA† OCRBench DocVQA MME MMVet RealWorldQA POPE MathVista MathVerse Avg. Vanilla 79.8 81.4 95.1 2316 61.6 68.6 86.7 68.2 44.3 100% Down-Sample (1/4) 2.5 45.3 88.8 2277 45.4 64.6 84.7 45.8 32.4 74.3% VisionThink (Ours) 79.8 80.8 94.4 2400 67.1 68.5 86.0 66.8 48.0 102.0% SparseVLM 73.2 75.6 66.8 2282 51.5 68.4 85.5 66.6 45.1 92.2% FastV 72.6 75.8 93.6 2308 52.8 68.8 84.7 63.7 45.0 95.8% Table 1: Performance comparison with existing efficient VLMs. VisionThink achieves an average performance (102%) surpassing the baseline (Vanilla) while keeping total visual tokens below 60%. A key feature is the minimal performance degradation on OCR-related tasks (ChartQA, OCRBench).
-
Result 3: Faster Inference VisionThink also showed a significant advantage in terms of inference time. The figure below compares it with a model that always infers at high resolution (Qwen-RL) and one that always infers at 1/4 resolution (Qwen-RL 1/4). VisionThink achieved inference speeds close to the 1/4 resolution model on many tasks and was significantly faster than the high-resolution model.
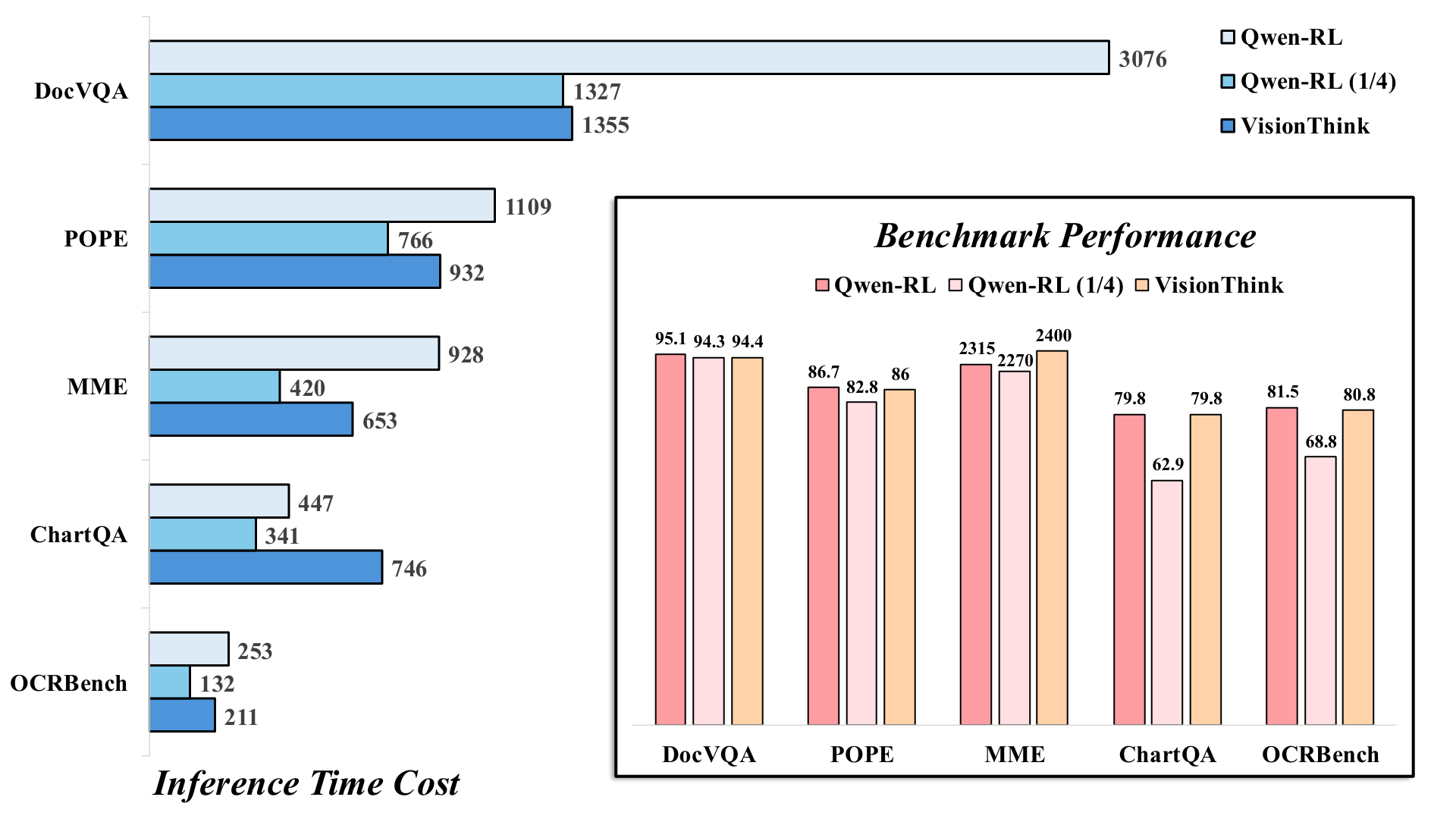 Figure 4: Comparison of inference time and performance. The blue bars represent performance, and the orange bars represent inference time. VisionThink achieves performance comparable to or better than the high-resolution model at a speed close to the 1/4 resolution model.
Figure 4: Comparison of inference time and performance. The blue bars represent performance, and the orange bars represent inference time. VisionThink achieves performance comparable to or better than the high-resolution model at a speed close to the 1/4 resolution model.
Applications and Future Outlook
Potential Applications
The results of this research will promote the use of VLMs in environments with limited computational resources.
- Application 1: AI on Edge Devices: Enables high-speed, high-performance visual assistants on devices like smartphones and smart glasses.
- Application 2: Autonomous Driving & Robotics: Allows for the construction of efficient systems that can quickly assess the surrounding situation and only increase processing load when detailed confirmation, such as for traffic signs, is necessary.
Business Outlook
The results of this research have the potential to significantly improve the cost-performance of VLM-based services.
- Operational Efficiency: Reduces server costs for providing VLM as a service, allowing it to be offered to more users at a lower price.
- Improved User Experience: The improved response speed enhances the user experience in applications that require real-time performance.
Future Challenges
Although this research has achieved significant results, there is still room for development.
- More Flexible Resolution Selection: Currently, it's a two-stage "low" and "high" selection, but a system that more flexibly uses multiple resolutions depending on the task could be considered.
- Integration of Other Visual Tools: By integrating other tools like "cropping a specific area of an image" in addition to resolution changes, an even more efficient and high-performance model can be expected.
Conclusion
This paper proposed "VisionThink," a new paradigm that balances the efficiency and performance of VLMs. By using reinforcement learning to enable the model to autonomously switch image resolution based on task difficulty, it succeeded in significantly reducing computational costs for simple tasks while maintaining high performance for complex ones. This "smart" approach greatly enhances the practicality of VLMs and points to a new direction for future AI research and development.
Notes
- Vision-Language Model (VLM): An AI model that can understand and process both images (visual information) and text (language information).
- Reinforcement Learning (RL): A machine learning method where an AI (agent) learns through trial and error within an environment to take actions (a policy) that maximize a reward.
- Visual Tokens: An image divided into small patches (fragments) to make it easier for AI to process. A higher number of tokens allows for more detailed information but increases computational cost.
- OCR: Stands for Optical Character Recognition. A technology that recognizes characters in images or documents and converts them into text data.
- VQA: Stands for Visual Question Answering. A task where an AI answers questions about the content of an image.
- LLM-as-Judge: A technique used in tasks that are difficult to evaluate, where a Large Language Model (LLM) is used as a "judge" to assess the quality or correctness of generated output.
- GRPO: Stands for Group Relative Policy Optimization. A type of reinforcement learning algorithm that updates a policy to favor the generation of better outcomes by comparing multiple generated results as a group.
Related Posts
2025-08-13
This paper presents a large-scale, systematic comparison and analysis of the performance of Transformer models, which have recently gained attention, and conventional mainstream CNN models for object detection tasks using remote sensing data such as satellite imagery. The study evaluates 11 different models on three datasets with distinct characteristics, revealing the potential for Transformers to outperform CNNs and clarifying the trade-off with the associated training costs.
2025-08-13
This study investigates whether deep learning models can predict a patient's self-reported race from skin histology images, examining the potential for demographic biases that AI may unintentionally learn. Through attention analysis, it reveals that the model uses specific tissue structures like the 'epidermis' as cues (shortcuts) to predict race. These findings highlight the importance of data management and bias mitigation for the fair implementation of medical AI in society.
2025-08-13
This paper proposes a new benchmark, 'Document Haystack,' which measures the ability to find specific information from long documents up to 200 pages long. This benchmark evaluates how accurately a Vision Language Model (VLM) can find intentionally embedded text or image information ('needles') within a document. The experimental results reveal that while current VLMs perform well on text-only documents, their performance significantly degrades on imaged documents or when handling information that combines text and images. This highlights future research challenges in the long-context and multimodal document understanding capabilities of VLMs.