Performance Evaluation and Analysis of Deep Learning Transformers and CNNs on Modern Remote Sensing Datasets
2025-08-13
Citation: http://arxiv.org/pdf/2508.02871v1
Authors and Affiliations
- J. Alex Hurt
- Trevor M. Bajkowski
- Grant J. Scott
- Curt H. Davis (Affiliations are not specified in the paper)
Paper Summary
This paper, "Evaluation and Analysis of Deep Neural Transformers and Convolutional Neural Networks on Modern Remote Sensing Datasets," is a study focusing on object detection from satellite images, a critical task in the field of remote sensing. This research systematically compares and analyzes the performance of the Transformer architecture, which has recently garnered significant attention in the computer vision field, and the Convolutional Neural Network (CNN), the conventional standard technology, within the specialized domain of satellite imagery.
Research Objective: The primary goal of this research is to clarify which is superior for object detection tasks in satellite imagery—Transformers or CNNs—and what their characteristics are. It also aims to elucidate the trade-off between performance and computational cost (training time) to provide practical guidance for researchers and developers in the remote sensing field to select models suited to their objectives.
Research Background: Since the advent of AlexNet in 2012, CNNs have dominated the field of image recognition. However, in recent years, the Transformer architecture, originating from the natural language processing field, has been applied to image recognition (e.g., Vision Transformer) and has begun to show performance surpassing CNNs in many tasks. However, many of these achievements were obtained on general ground-level photo datasets. Satellite images possess different characteristics from ground-level photos, such as a top-down perspective, diverse scales, and unique object arrangements. Therefore, it was not clear whether Transformers could demonstrate similar superiority for satellite imagery. This study conducted a large-scale comparative experiment to fill that gap.
Highlights of the Study: This study's value lies not in proposing a specific new technology but in its thorough comparative evaluation. The highlights are as follows:
- Comprehensive Model Selection: A total of 11 major object detection models, including 5 Transformer-based and 6 CNN-based models, are targeted for evaluation.
- Evaluation on Diverse Datasets: By using three public remote sensing datasets with different sizes and complexities (RarePlanes, DOTA, xView), the study deeply analyzes the models' generalization capabilities and data dependencies.
- Detailed Performance Analysis: The analysis goes beyond simple accuracy comparisons to include practical aspects such as training time and model complexity.
 Figure 1: Sample images from the three datasets used for evaluation in this study. From top to bottom: RarePlanes (aircraft), DOTA (diverse objects), and xView (high-density objects). It is clear that the type, size, and density of objects differ significantly across datasets.
Figure 1: Sample images from the three datasets used for evaluation in this study. From top to bottom: RarePlanes (aircraft), DOTA (diverse objects), and xView (high-density objects). It is clear that the type, size, and density of objects differ significantly across datasets.
Related Work
Review of Prior Research
In this study, representative models from the two major architectures in object detection, CNN and Transformer, were selected.
-
CNN-based Models (6 types):
- Faster R-CNN: A leading two-stage detection method that first proposes "regions likely to contain objects" and then classifies those regions in detail.
- SSD (Single Shot Detector): A fast single-stage detector that simultaneously predicts object location and class in a single pass.
- RetinaNet: Solved the imbalance in learning between "easy backgrounds" and "important objects," a challenge for single-stage detectors, with a technique called "Focal Loss."
- YOLOv3, YOLOX: A series famous for extremely fast real-time object detection, as the name "You Only Look Once" suggests.
- FCOS: An anchor-free method that does not use anchor boxes (initial candidates for object locations), simplifying the design.
- ConvNeXt: A new CNN architecture that improves performance by incorporating design principles from Transformers into CNNs.
-
Transformer-based Models (5 types):
- Vision Transformer (ViT): A pioneering model that demonstrated the potential of Transformers in image recognition by dividing an image into patches, like words, and feeding them into a Transformer.
- SWIN Transformer: A more practical Transformer model that improves the computational cost of ViT and can capture hierarchical features.
- DETR (DEtection TRansformer): The first end-to-end model that constructs the entire object detection process with a Transformer.
- Deformable DETR: A model that improves the performance and convergence speed of DETR with a more efficient attention mechanism.
- CO-DETR: A state-of-the-art model that introduces a new training method to further enhance the learning efficiency of DETR-based models.
| Detector | Type | Backbone | Parameters (M) | APCOCO | Release Year |
|---|---|---|---|---|---|
| ConvNeXt SSD RetinaNet FCOS YOLOv3 YOLOX | Two-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN Single-Stage CNN | ConvNeXt-S VGG-16 ResNeXt-101 ResNeXt-101 DarkNet-53 YOLOX-X | 67.09 36.04 95.47 89.79 61.95 99.07 | 51.81 29.5 41.6 42.6 33.7 50.9 | 2022 2016 2017 2019 2018 2021 |
| ViT DETR Deformable DETR SWIN CO-DETR | Transformer Transformer Transformer Transformer Transformer | ViT-B ResNet-50 ResNet-50 SWIN-T SWIN-L | 97.62 41.30 40.94 45.15 218.00 | N/A2 40.1 46.8 46.0 64.1 | 2020 2020 2020 2021 2023 |
Table 1: A comparison of the detection methods investigated in this study, summarizing their type, backbone (feature extractor), number of parameters, performance on the COCO dataset (AP), and release year.
Differences Between Prior Research and This Study
Unlike prior research that develops individual models, this study is significantly different in that it transversely evaluates and analyzes these diverse models in the specific application domain of remote sensing. This approach clarifies the behavior of each model against challenges unique to satellite imagery, which might not be apparent on general datasets.
Novelty and Contributions of the Paper
Novelty
This study offers a new perspective compared to existing research in the following ways:
- First Large-Scale Comparison: This is the first study to compare the object detection performance of Transformers and CNNs in the remote sensing field on such a large and systematic scale.
- Validation Under Diverse Conditions: By using three datasets with different characteristics, it assesses from multiple angles where models are strong and where they are weak.
- Comprehensive Coverage of a-of-the-art Models: It is highly comprehensive, covering 11 models, including the latest architectures like CO-DETR, announced in 2023.
Contribution
This study makes the following academic and practical contributions:
- Provides Guidance for Model Selection: It offers concrete data and insights for researchers and practitioners in the remote sensing field to select the optimal model based on project requirements (accuracy, speed, etc.).
- Demonstrates the Effectiveness of Transformers: It proves that Transformer models hold high potential for satellite imagery, thereby accelerating applied research in this field.
- Publishes Pre-trained Models: The authors have released the weights of the 33 models trained in this study, allowing other researchers to utilize them for transfer learning and directly contributing to the development of the entire community.
Evaluation and Discussion
Evaluation Method
The following evaluation methods were adopted to verify the effectiveness of the proposed approaches.
- Analysis Method: Compared the performance of 5 Transformer-based models and 6 CNN-based models across three datasets.
- Datasets:
- RarePlanes: A small-scale dataset specialized in aircraft (approx. 25,000 objects).
- DOTA: A medium-scale dataset containing diverse objects across 16 classes (approx. 280,000 objects).
- xView: A large-scale and highly challenging dataset with densely packed objects across 60 classes (approx. 1 million objects).
- Evaluation Metrics:
- Optimal F1 Score: An indicator that balances precision and recall, representing the overall detection accuracy of the model.
- AP (Average Precision): A standard performance metric used in object detection tasks. AP50 is the AP when an intersection over union (IoU) of 50% or more is considered a correct detection.
- AR (Average Recall): The recall rate, which indicates how well the model detected objects without missing them.
Research Results
The study yielded the following important findings.
1. Transformers Are Also Strong in Remote Sensing Across all datasets, the best-performing models were Transformer-based.
- RarePlanes (small-scale): SWIN Transformer achieved the highest F1 score (81.70%).
- DOTA (medium-scale): CO-DETR achieved the highest F1 score (73.53%).
- xView (large-scale): SWIN Transformer achieved the highest F1 score (34.04%).
| Model | P | F1 | AP | AP50 | AR | AR50 |
|---|---|---|---|---|---|---|
| SWIN | 45 | 81.70 | 59.04 | 73.71 | 61.94 | 74.47 |
| YOLOX | 99 | 77.14 | 54.84 | 66.27 | 58.22 | 68.71 |
| CO-DETR | 218 | 70.71 | 56.60 | 67.95 | 79.74 | 97.59 |
Table 3 (Partial Excerpt): Performance on the RarePlanes dataset. SWIN Transformer was top in F1 score. Meanwhile, CO-DETR showed the characteristic of having extremely few missed detections (AR50 of 97.59%).
2. A Trade-off Exists Between Performance and Computational Cost A trend was observed where models that deliver higher performance require more time for training.
- CO-DETR: Achieved the highest performance on the DOTA dataset but had the slowest training speed (5.02 FPS).
- YOLOX: Achieved performance comparable to CO-DETR at about three times the speed (14.74 FPS), showing an excellent balance.
- YOLOv3: While its performance is moderate, it is extremely fast (45.5 FPS), making it suitable for applications requiring real-time capabilities.
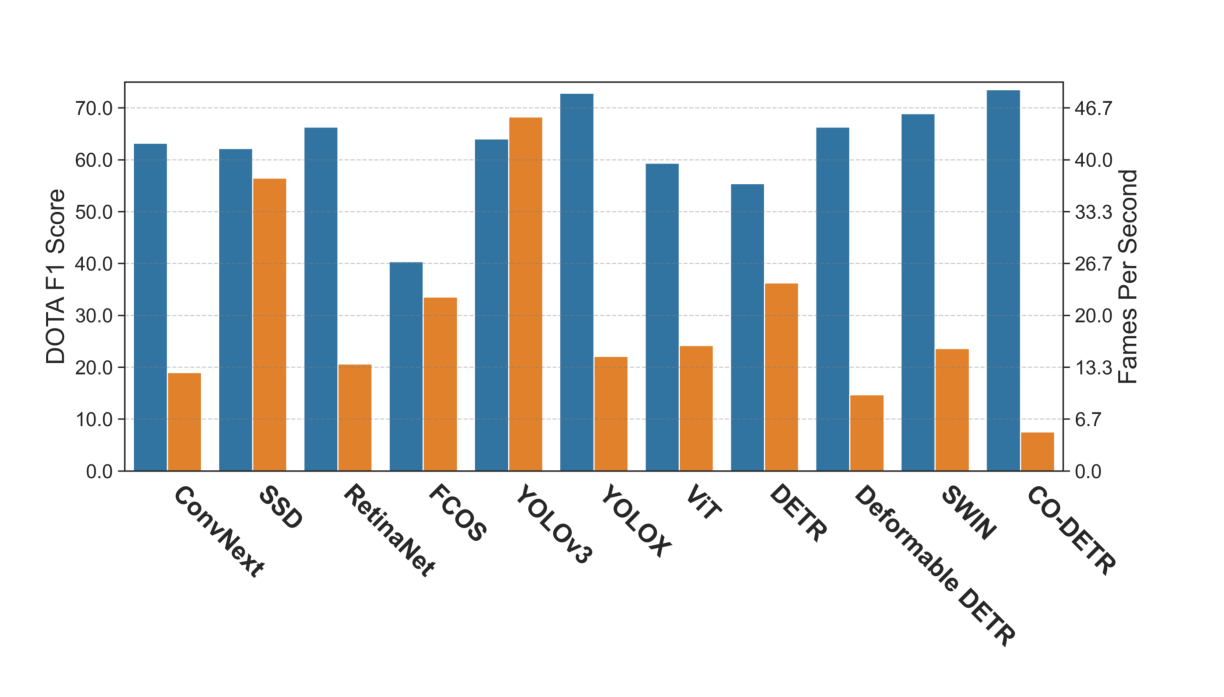 Figure 3: Comparison of F1 score (blue) and training speed (orange, FPS) on the DOTA dataset. A clear trade-off is shown: high-performance models (e.g., CO-DETR) are slow, while fast models (e.g., YOLOv3) have slightly lower performance.
Figure 3: Comparison of F1 score (blue) and training speed (orange, FPS) on the DOTA dataset. A clear trade-off is shown: high-performance models (e.g., CO-DETR) are slow, while fast models (e.g., YOLOv3) have slightly lower performance.
3. Transformers Demonstrate More Stable Performance While some CNN models showed significant performance fluctuations depending on the dataset (e.g., FCOS), Transformer models tended to exhibit relatively stable performance. In particular, SWIN, YOLOX, and CO-DETR consistently maintained top-class performance across all datasets.
4. Case Study: CNN Backbone vs. Transformer Backbone A comparison was made using the same detection algorithm (RetinaNet) but swapping the backbone (feature extractor) between a CNN (ResNeXt-101) and a Transformer (ViT).
- On the medium-sized DOTA dataset, the CNN version performed better.
- On the large-scale xView dataset, the performance gap between the two narrowed. This supports the findings of prior research that "Transformers require more data to reach their full potential."
Applications and Future Prospects
Potential Applications
The results of this research are expected to have applications in various practical fields that utilize satellite imagery.
- Disaster Prevention and Response: Automatically assessing building damage after earthquakes or floods.
- Environmental Monitoring: Monitoring illegal deforestation or urban expansion over wide areas.
- National Security: Automatically tracking and analyzing the activities of specific facilities or vehicles.
- Agriculture and Fisheries: Efficiently managing crop growth status and aquaculture farms.
Business Outlook
The findings of this research are expected to be utilized in the following business areas:
- Development of New Products and Services: New geographic information services and insurance assessment tools incorporating high-precision satellite data analysis.
- Operational Efficiency: Automating the inspection and management of vast infrastructures (pipelines, power grids, etc.) to reduce costs.
- Market Impact: Lowering the barrier to entry for satellite data utilization, creating and expanding markets in diverse industries such as agriculture, finance, and real estate.
Future Challenges
While this study has made significant contributions, the following challenges are envisioned for further advancement:
- Reduction of Computational Costs: Technologies to efficiently train and operate high-performance Transformer models with fewer computational resources.
- Handling of Minority Classes and Tiny Objects: How to accurately detect classes that are rare in the dataset or extremely small objects.
- Improved Generalization: Research to ensure that models trained on specific regions or sensors function stably under different conditions.
Conclusion
This paper has clearly demonstrated through extensive and systematic experiments that in object detection tasks for remote sensing (satellite imagery), the Transformer architecture has the potential to surpass the performance of conventional CNNs.
In particular, models such as SWIN Transformer, YOLOX, and CO-DETR were found to deliver consistently high performance regardless of dataset characteristics. On the other hand, it was also clarified that this high performance comes with the computational cost of increased training time, making model selection based on the trade-off between performance and cost essential for practical implementation.
This study is an important milestone that indicates the future direction of next-generation object detection technology in the remote sensing field, providing valuable insights and resources (pre-trained models) that will accelerate research and development in this area.
Notes
- Transformer: A model that learns the relationships between different parts (patches) of an image, similar to how context is read to understand the meaning of words. It was originally developed for natural language processing.
- CNN (Convolutional Neural Network): A network that excels at extracting local features like edges and patterns by scanning an image with small filters. It is the standard model for image recognition.
- Object Detection: The task of identifying "what" (class) is in an image and "where" (location) it is.
- Remote Sensing: The technology of observing the Earth's surface from aircraft or satellites. This study specifically focuses on satellite imagery.
- F1 Score: A metric that evaluates a model's performance by balancing "low number of misses (recall)" and "low number of false detections (precision)."
- AP (Average Precision): A commonly used metric to evaluate the overall performance of object detection models; a higher value indicates better performance.
Related Posts
2025-08-13
This study investigates whether deep learning models can predict a patient's self-reported race from skin histology images, examining the potential for demographic biases that AI may unintentionally learn. Through attention analysis, it reveals that the model uses specific tissue structures like the 'epidermis' as cues (shortcuts) to predict race. These findings highlight the importance of data management and bias mitigation for the fair implementation of medical AI in society.
2025-08-13
This paper proposes a new benchmark, 'Document Haystack,' which measures the ability to find specific information from long documents up to 200 pages long. This benchmark evaluates how accurately a Vision Language Model (VLM) can find intentionally embedded text or image information ('needles') within a document. The experimental results reveal that while current VLMs perform well on text-only documents, their performance significantly degrades on imaged documents or when handling information that combines text and images. This highlights future research challenges in the long-context and multimodal document understanding capabilities of VLMs.
2025-08-13
This paper proposes BF-PIP, a zero-shot method that utilizes Google's Gemini 2.5 Pro to predict pedestrian crossing intention without any additional training. Unlike conventional frame-based methods, it directly uses short, continuous videos and metadata such as ego-vehicle speed, achieving a high accuracy of 73% and demonstrating the potential for robust intention prediction based on contextual understanding.