Seeing Beyond Frames: Zero-Shot Pedestrian Intention Prediction with Raw Temporal Video and Multimodal Cues
2025-08-13
Citation: http://arxiv.org/pdf/2507.21161v1
Authors and Affiliations
- Ying Liu: Department of Computer Science, Texas Tech University
- Pallavi Zambare: Department of Computer Science, Texas Tech University
- Venkata Nikhil Thanikella: Department of Computer Science, Texas Tech University
Paper Summary
This paper, "Seeing Beyond Frames: Zero-Shot Pedestrian Intention Prediction with Raw Temporal Video and Multimodal Cues," focuses on a critical challenge in autonomous driving technology: predicting pedestrian crossing intention. To address this challenge, the study proposes a new zero-shot approach, "BF-PIP," which leverages Google's latest Multimodal Large Language Model (MLLM), Gemini 2.5 Pro.
Research Objective: The main objective of this research is to overcome the problems inherent in conventional intention prediction models, such as the need for large amounts of pre-training data and low adaptability to new environments. To achieve this, the study aims to build a framework that directly and accurately predicts pedestrian intention from continuous video footage and multiple information sources (multimodal cues) through "zero-shot learning," without any additional training.
Research Background: For autonomous vehicles to navigate urban areas safely, it is essential to accurately predict the next actions of pedestrians, especially whether they will cross the road. Previous research has used models like RNNs and Transformers to predict pedestrian movement, but these methods require training on specific datasets and have difficulty responding to unknown situations not present in the training data. In recent years, MLLMs like GPT-4V have emerged, making zero-shot prediction increasingly possible. However, these still process sequences of still images (frame sequences) and may miss the subtle nuances that can only be captured in continuous video, such as a pedestrian's "hesitation" or "gaze movement."
Highlights of the Proposed Method: The most important features of the "BF-PIP" method proposed in this study are as follows:
- Direct Processing of Continuous Video: Instead of being based on still images, it uses short video clips as direct input. This allows it to richly capture the continuity of motion and temporal context, leading to a more natural understanding of the situation.
- Zero-shot Inference: It leverages the powerful general-purpose capabilities of Gemini 2.5 Pro, completely eliminating the need for additional training or fine-tuning on specific datasets. This reduces development costs and enables rapid response to unknown scenarios.
- Utilization of Multimodal Cues: In addition to video footage, it incorporates additional contextual information into the prompt, such as bounding boxes indicating the pedestrian's location and the ego-vehicle's speed, thereby improving prediction accuracy.
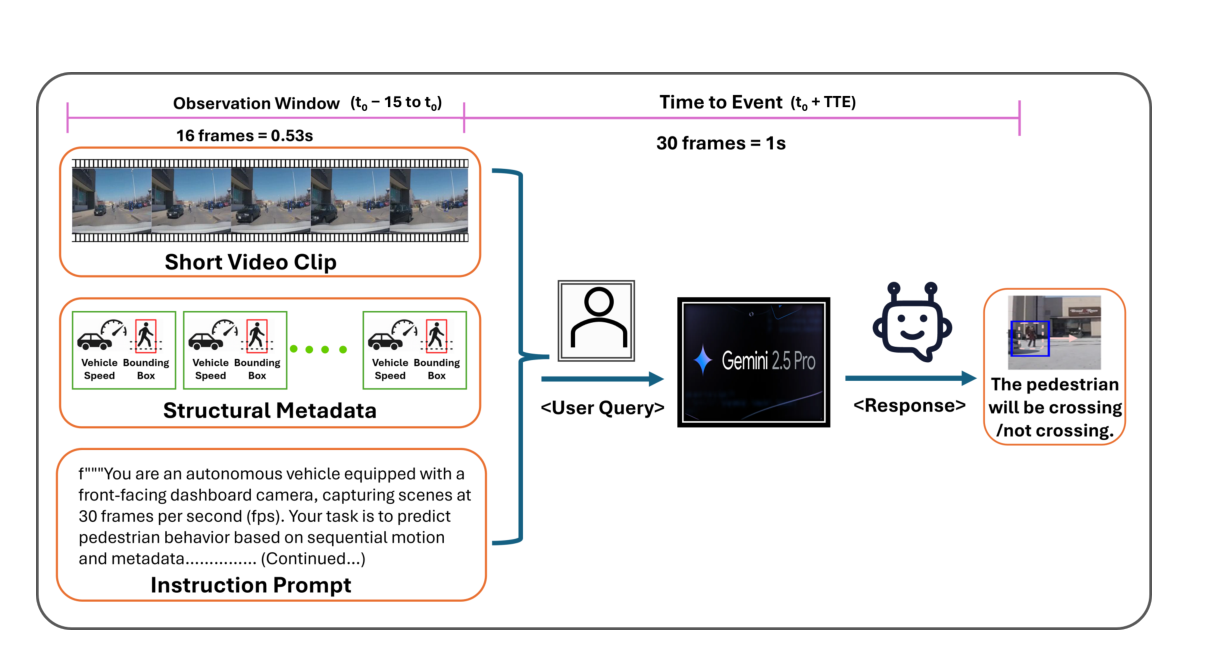 Figure 1: Overview diagram of the BF-PIP framework. Multimodal information, such as a short video clip, bounding box, and ego-vehicle speed, is input as a prompt to Gemini 2.5 Pro, which predicts the pedestrian's crossing intention (Crossing/Not Crossing) in a zero-shot manner.
Figure 1: Overview diagram of the BF-PIP framework. Multimodal information, such as a short video clip, bounding box, and ego-vehicle speed, is input as a prompt to Gemini 2.5 Pro, which predicts the pedestrian's crossing intention (Crossing/Not Crossing) in a zero-shot manner.
Related Work
Review of Prior Research
- Conventional Methods (RNN, GCN, Transformer-based): These models predict intention by learning time-series data such as pedestrian trajectories and poses. While some achieve high performance, they require supervised learning on large-scale labeled datasets and have issues with generalization.
- MLLM-based Methods (GPT4V-PBP, OmniPredict): These studies use MLLMs like GPT-4V and GPT-4o to perform zero-shot intention prediction. They represent a significant advancement but are limited to sequences of still images as input, thus not fully utilizing the continuous motion information that video provides.
Differences Between Prior Research and This Study
This study takes a step beyond previous MLLM-based methods, with the key difference being that it directly inputs raw continuous video clips into the model. This allows it to capture temporal dynamics, such as hesitation and gaze shifts, that were not fully captured by prior research, enabling predictions based on a more realistic situational awareness.
Novelty and Contributions of the Paper
Novelty
This research offers a new perspective compared to existing studies in the following ways:
- Novelty 1: It proposes the world's first framework to predict pedestrian intention directly from raw continuous video clips in a zero-shot manner using an MLLM (Gemini 2.5 Pro).
- Novelty 2: It designs an effective multimodal prompt that combines video information with structured metadata, such as bounding boxes and ego-vehicle speed, significantly improving the model's spatio-temporal understanding and reasoning accuracy.
Contributions
This research makes the following academic and practical contributions:
- Contribution 1: It presents an approach that eliminates the need for costly and time-consuming retraining in the development of perception modules for autonomous driving systems. This enables more agile development.
- Contribution 2: It achieves accuracy surpassing existing state-of-the-art MLLM-based methods on a standard benchmark dataset (JAAD), demonstrating the effectiveness of zero-shot inference that directly utilizes video.
Details of the Proposed Method
Method Overview
This paper proposes BF-PIP (Beyond Frames Pedestrian Intention Prediction). This method fully leverages the advanced multimodal capabilities of Gemini 2.5 Pro, which can process video, images, and text in a single prompt.
Methodology Components
The proposed method consists of the following steps:
- Task Definition: Pedestrian crossing intention prediction is framed as a binary classification problem: "to cross" or "not to cross." The prediction is made 1 second (30 frames) before the action occurs, using a video clip of the preceding ~0.5 seconds (16 frames) as observational data.
- Preparation of Multimodal Inputs:
- Short Video Clip: A 16-frame continuous video for observation is prepared.
- Bounding Box Coordinates: The coordinates of a rectangular area to identify the pedestrian's location. These are either drawn directly on the video (annotated) or provided as text information.
- Ego-vehicle Speed: The speed of the ego-vehicle (e.g., accelerating, decelerating, constant speed) is added as contextual information.
- Prompt Design and Inference Strategy:
- A role-playing prompt is adopted, assigning Gemini 2.5 Pro the role: "You are the camera of an autonomous vehicle."
- The prompt clearly instructs the model on the task, the format of the input data (16-frame video, bounding box, etc.), and the steps for thinking, such as "analyze the pedestrian's posture, movements, and surrounding situation."
- This structured prompt and the video are given as input to Gemini 2.5 Pro to perform inference. The output is specified in JSON format to maintain consistency.
Evaluation and Discussion
Evaluation Method
The following evaluation methods were adopted to verify the effectiveness of the proposed approach:
- Dataset: The
JAADbehsubset of the JAAD (Joint Attention in Autonomous Driving) dataset, widely used in autonomous driving research and specifically focused on crossing behaviors, was used. - Experimental Setup: Zero-shot inference was evaluated using 126 test clips. Experiments were conducted under two conditions: "Annotated" videos with the pedestrian's location explicitly marked, and "Unannotated" videos with nothing drawn on them.
- Evaluation Metrics: Performance was assessed using five standard metrics: Accuracy, AUC (Area Under the ROC Curve), F1-score, Precision, and Recall.
Research Results
The study yielded the following important findings:
Quantitative Results Despite no additional training, BF-PIP demonstrated exceptionally high performance compared to existing specialized models and MLLM-based methods.
- Highest Accuracy: The proposed method achieved 73% accuracy and an AUC of 0.76, outperforming the state-of-the-art MLLM-based model, OmniPredict (67% accuracy), by 6%.
- High Reliability: In particular, Precision reached an astounding 0.96. This means that when the model predicts "to cross," the prediction is highly reliable.
| Models | Year | Model Variants | Inputs | JAAD-beh |
|---|---|---|---|---|
| Models | Year | Model Variants | I B P S V Extra Info. | ACC AUC F1 P R |
| MultiRNN [3] | 2018 | GRU | ✓ ✓ ✓ – – | 0.61 0.50 0.74 0.64 0.86 |
| ... | ... | ... | ... | ... |
| GPT4V-PBP [15] | 2023 | MLLM | ✓ ✓ – – – Text | 0.57 0.61 0.65 0.82 0.54 |
| OmniPredict [14] | 2024 | MLLM | ✓ ✓ – ✓ – Text | 0.67 0.65 0.65 0.66 0.65 |
| BF-PIP(Ours) | 2025 | MLLM | – ✓ – ✓ ✓ Text | 0.73 0.77 0.80 0.96 0.69 |
Table 1: Performance comparison with existing state-of-the-art methods. BF-PIP (in bold) uses video (V) as a primary input and achieves high performance in accuracy (ACC), AUC, F1-score, and Precision (P).
Qualitative Results Analysis of how the model makes its judgments revealed that Gemini 2.5 Pro understands context deeply, much like a human.
- Complex Situational Judgment: In the example in Figure 2, the model correctly predicted "to cross" by integrating multiple cues, such as the pedestrian being near a crosswalk, leaning their body toward the road, and their gaze movement to check for oncoming traffic.
 Figure 2: Example of qualitative analysis of pedestrian crossing intention. The model captures multiple factors such as the pedestrian's posture (leaning forward), direction of gaze (checking traffic), and subtle movements (a step towards the crosswalk) to make a comprehensive judgment of the crossing intention.
Figure 2: Example of qualitative analysis of pedestrian crossing intention. The model captures multiple factors such as the pedestrian's posture (leaning forward), direction of gaze (checking traffic), and subtle movements (a step towards the crosswalk) to make a comprehensive judgment of the crossing intention.
Ablation Study By varying the types of input information, the study investigated which elements contributed to performance.
- Importance of Video and Speed Information: The combination of annotated video (AV) and ego-vehicle speed (S) achieved the highest accuracy (0.73) and F1-score (0.80). This confirms that both visual guidance (bounding box) and motion context (ego-vehicle speed) are essential for high-precision prediction.
| Input Modality | ACC | AUC | F1 | P | R |
|---|---|---|---|---|---|
| UV (Unannotated Video) | 0.65 | 0.62 | 0.74 | 0.96 | 0.60 |
| UV + S (+ Speed) | 0.70 | 0.74 | 0.78 | 0.97 | 0.65 |
| AV (Annotated Video) | 0.64 | 0.61 | 0.73 | 0.95 | 0.59 |
| AV + S (+ Speed) | 0.73 | 0.76 | 0.80 | 0.96 | 0.69 |
Table 2: Ablation study on input modalities. The combination of annotated video (AV) with ego-vehicle speed (S) showed the highest performance.
Applications and Future Prospects
Potential Applications
The results of this research are expected to have applications in various fields.
- Application 1: Perception and prediction systems for safer and more reliable autonomous vehicles.
- Application 2: Intelligent Transportation Systems (ITS) and traffic monitoring systems to enhance safety at intersections and on roads.
Business Prospects
The outcomes of this research are expected to be utilized in the following business areas:
- Development of new products and services: Realization of advanced driver-assistance systems and fully autonomous driving systems that can understand situations and predict hazards like a human driver.
- Operational efficiency improvement: Significantly reducing the enormous cost and time associated with data labeling and model retraining, thereby shortening the AI development cycle.
- Market impact: Bringing agile AI development methodologies based on zero-shot learning to the transportation sector, potentially establishing a technological competitive advantage.
Future Challenges
Although this research has achieved significant success, a future challenge is handling more complex scenarios. Examples include situations with multiple pedestrians present simultaneously, performance verification under adverse conditions like bad weather or nighttime, and optimization of computational costs to ensure real-time performance.
Conclusion
This paper proposed a new framework, "BF-PIP," which utilizes the multimodal capabilities of Gemini 2.5 Pro to predict pedestrian crossing intention from raw continuous video clips in a zero-shot manner. By achieving higher accuracy than existing state-of-the-art methods without any additional training, this study has moved beyond the analysis of static frames and demonstrated the importance of richly capturing temporal context. This achievement is a significant step towards realizing safer and more efficient autonomous driving systems and is expected to have a major impact on future AI development.
Notes
- Zero-shot Learning: The ability of a model to perform tasks or categorize items it has not been trained on, without any prior additional training. It indicates high generalizability.
- Multimodal LLM (MLLM): A large language model that can simultaneously understand and process multiple different types of information (modalities), such as text, images, video, and audio. Gemini 2.5 Pro was used in this study.
- Bounding Box: A rectangular region in an image or video that encloses a specific object (in this study, a pedestrian). It indicates the object's position and size.
- Prompt: A text input given to a large language model to instruct it or provide context for performing a specific task. The design of the prompt significantly affects the model's performance.
- Ablation Study: An experimental technique used to analyze the importance of each component of a model or system by systematically removing one component at a time and observing how performance changes.
- JAAD (Joint Attention in Autonomous Driving): A video dataset widely used in autonomous driving research, with detailed annotations regarding pedestrian behavior and intentions.
Related Posts
2025-08-13
This paper presents a large-scale, systematic comparison and analysis of the performance of Transformer models, which have recently gained attention, and conventional mainstream CNN models for object detection tasks using remote sensing data such as satellite imagery. The study evaluates 11 different models on three datasets with distinct characteristics, revealing the potential for Transformers to outperform CNNs and clarifying the trade-off with the associated training costs.
2025-08-13
This study investigates whether deep learning models can predict a patient's self-reported race from skin histology images, examining the potential for demographic biases that AI may unintentionally learn. Through attention analysis, it reveals that the model uses specific tissue structures like the 'epidermis' as cues (shortcuts) to predict race. These findings highlight the importance of data management and bias mitigation for the fair implementation of medical AI in society.
2025-08-13
This paper proposes a new benchmark, 'Document Haystack,' which measures the ability to find specific information from long documents up to 200 pages long. This benchmark evaluates how accurately a Vision Language Model (VLM) can find intentionally embedded text or image information ('needles') within a document. The experimental results reveal that while current VLMs perform well on text-only documents, their performance significantly degrades on imaged documents or when handling information that combines text and images. This highlights future research challenges in the long-context and multimodal document understanding capabilities of VLMs.