赤ずきんちゃんの登場人物と感情をLangExtractで抽出してみた
2025-08-10
1. はじめに
-
この記事を書いた理由
Googleが公開したGeminiモデル対応の情報抽出ライブラリ「LangExtract」に興味を持ち、童話『赤ずきんちゃん』を題材に実際に試してみました。 -
LangExtractとは?
LangExtractは、GoogleのGemini言語モデルを活用した最新の情報抽出ライブラリです。自然言語テキストから「登場人物」「感情」「関係性」などの構造化情報を効率的かつ高精度に抽出できるのが特徴です。
特に、few-shot学習やsource grounding、controlled generationなどの技術を組み合わせて、元テキストに即した信頼性の高い抽出を実現しています。 -
対象読者
自然言語処理や情報抽出に関心のある開発者・技術者の方。 -
この記事を読むと得られること
LangExtractを使った構造化情報抽出の方法や、その実践的な応用イメージがつかめます。
2. 全体概要
-
今回のテーマ
LangExtractを用いて、『赤ずきんちゃん』のテキストから「登場人物」「感情」「関係性」を抽出する実験を行います。 -
用語説明
- source grounding
テキスト内の元の位置情報を保ったまま抽出すること。 - controlled generation
出力のフォーマットや構造をコントロールして安定的に結果を得ること。 - few-shot learning
少数の例示データをもとに学習・抽出する手法。
- source grounding
-
技術背景
LangExtractはGeminiモデルを活用し、チャンク処理や並列抽出、多段階処理が可能な強力な情報抽出ライブラリです。
3. 実験:『赤ずきんちゃん』で抽出してみる
3.1 環境と使用モデル
- リポジトリ:
- 使用モデル:Gemini 系(例:
gemini-2.5-flash)
3.2 原文とfew-shot例の紹介
今回は以下の英語・日本語テキストを使い、それぞれにfew-shot例を用意しました。
(原文:https://www.grimmstories.com/language.php?grimm=026&l=ja&r=en)
英語のfew-shot例
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="LITTLE RED-CAP",
attributes={"role": "protagonist"},
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="I'll go visit my grandmother.",
attributes={"feeling": "resolved"},
),
]
日本語のfew-shot例
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="赤ずきん",
attributes={"role": "主人公"},
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="おばあさんのところへ行く",
attributes={"to": "おばあさん", "relationship": "訪問"},
),
]
3.3 抽出結果
日本語版の抽出結果例:
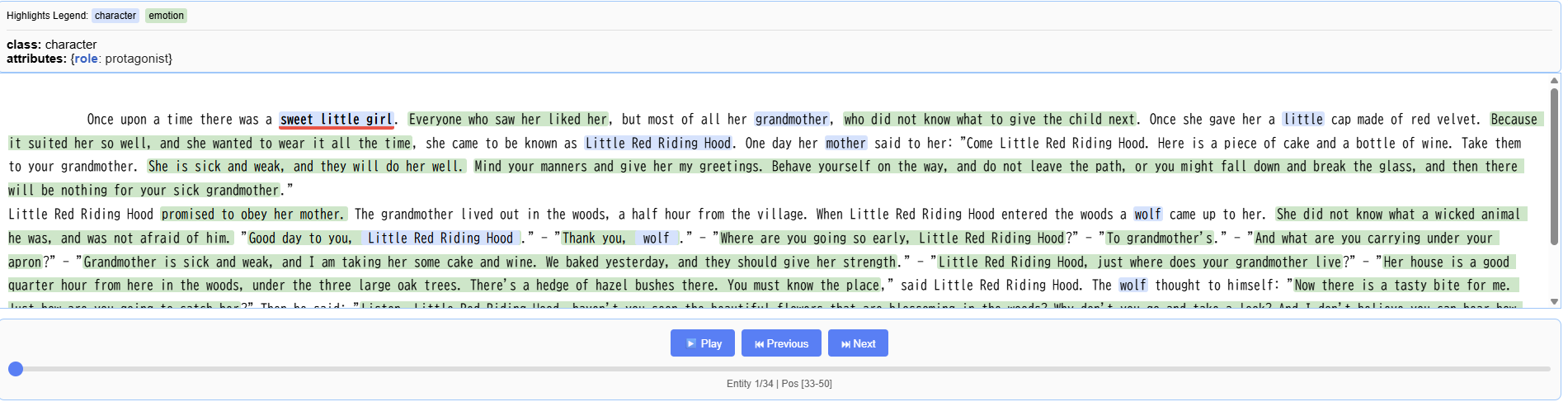
英語版の抽出結果例:
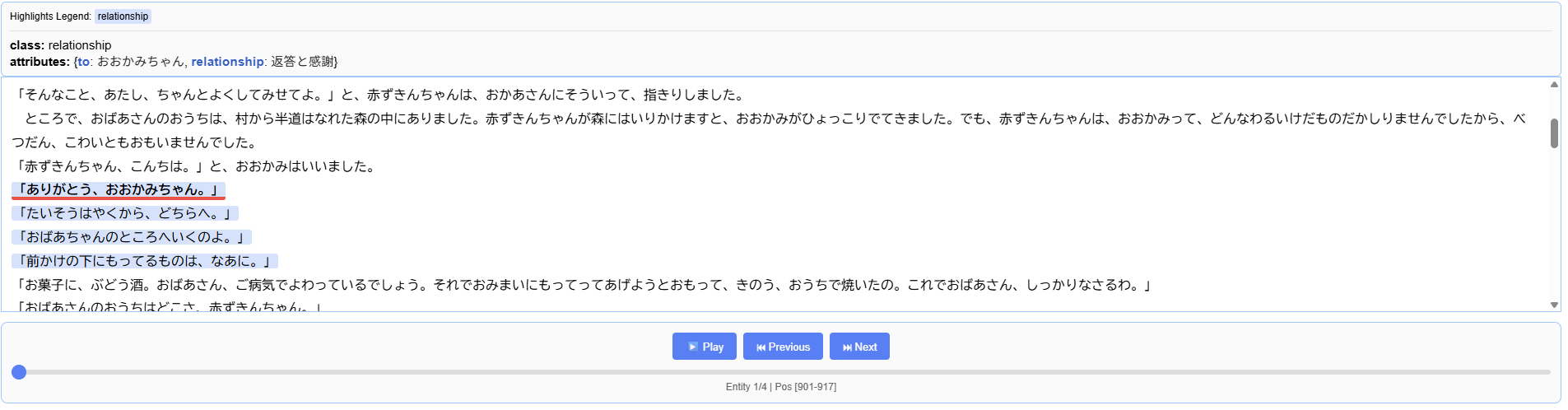
英語版は全体的に非常に良い精度で抽出できましたが、日本語版はnullが多く、多言語対応にはまだ改善の余地がある印象です。
4. まとめ
今回はLangExtractを使って童話『赤ずきんちゃん』から登場人物や感情、関係性を抽出しました。 Geminiモデルのfew-shot学習やsource grounding機能により、かなり高精度な構造化データが得られることを実感しました。
自然言語処理の実務や研究で、こうした情報抽出技術はとても役立つので、興味がある方はぜひ環境構築して試してみてください。
関連記事
2025-08-11
最新のPythonツールとAI自動化を融合し、効率的かつ高品質な開発を実現するテンプレートを紹介。 依存関係管理、コード品質保証、AI連携ワークフローで開発を加速します。
2025-08-09
Rorkは自然言語からネイティブなモバイルアプリを生成し、App Store/Google PlayへのビルドとデプロイをサポートするAIツールです。本記事では、家庭向け生活管理アプリの要件を実際にRorkに入力し、「生成→動作確認→ストア準備」までを試した流れと所感をまとめます。
2025-08-12
Anything(旧Create)は自然言語プロンプトからWeb/モバイル向けアプリを自動生成するAIプラットフォーム。実際の仕様例を入れて家庭向け生活管理アプリを“試作”する手順と評価をまとめました。