Robust and Fair Top-k Recommendations via Efficient and Responsible Adaptation of Large Language Models
2025-08-08
Authors and Affiliations
- Kirandeep Kaur (University of Washington, USA)
- Manya Chadha (University of Washington, USA)
- Vinayak Gupta (University of Washington, USA)
- Chirag Shah (University of Washington, USA)
Paper Summary
The paper Efficient and Responsible Adaptation of Large Language Models for Robust and Equitable Top-k Recommendations addresses two major challenges in recommendation systems:
- Bias in data leading to unfair recommendations
- High operational costs of large language models (LLMs)
Traditional recommendation systems apply a uniform approach to all users, which often results in lower accuracy for infrequent or minority-group users. While LLM-based recommendation systems offer high accuracy, they suffer from enormous computational and operational costs.
This study proposes a hybrid recommendation system combining traditional methods and LLMs. Users are first classified into "active users" and "weak users"; traditional methods are applied to active users, while LLMs are selectively used for weak users. This approach enhances fairness while keeping costs manageable.
Research Goals:
- Mitigate unfairness caused by data bias
- Reduce computational and operational costs when using LLMs
Background
Recommendation systems play a critical role in diverse services such as e-commerce, video streaming, and music platforms. Although accuracy improves with accumulated behavioral data, recommendation bias remains a concern. Over-recommending certain products can limit users' exposure to new options, reducing diversity.
Recently, LLMs like ChatGPT have gained attention for enabling sophisticated recommendations by leveraging natural language understanding. However, their high resource consumption and costs pose challenges for practical deployment compared to traditional methods.
Highlights of the Proposed Method
- A hybrid architecture combining traditional recommendation systems and LLMs
- User classification:
- Active users: frequent users recommended via traditional methods
- Weak users: infrequent users recommended via LLMs
- Minimizing LLM usage while improving recommendation accuracy for weak users
Related Work
Literature Review
- Fairness in recommendation systems: Proposals to avoid bias towards certain user or item attributes
- LLM-based recommendations: Utilizing reviews and descriptions to enable advanced natural language-driven recommendations
Positioning of This Study
Previous works addressed fairness and LLM cost issues separately. This study presents an approach that simultaneously tackles both challenges.
Novelty and Contributions
Novelty
- Introduction of the "weak user" concept based on data volume rather than attribute
- A hybrid recommendation system applying traditional methods to active users and LLMs to weak users, balancing fairness and cost-efficiency
Contributions
- Enhanced fairness by providing accurate recommendations to users underserved by traditional methods
- Promoted practical deployment by limiting LLM usage, thus reducing computational and operational costs
Method Details
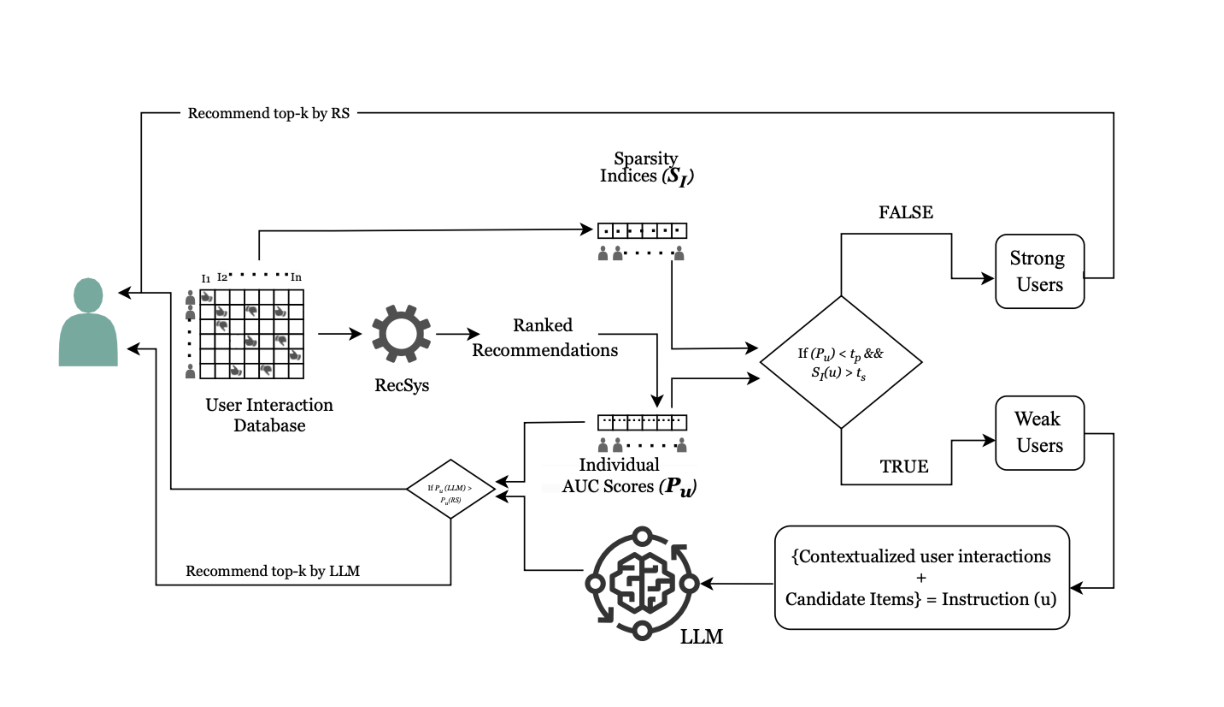
Step 1: User Classification
- Calculate AUC (Area Under the Curve) based on user activity history
- Users with low AUC → Weak users
- Users with high AUC → Active users
Step 2: Recommendation Approach
- Weak users → Recommendations generated by LLMs (GPT-4, Claude 3.5-haiku, LLaMA 3-70B-Instruct)
- Active users → Recommendations generated by traditional methods
Overall Pipeline
- Data preprocessing (extract user IDs, item IDs, and ratings)
- Train eight recommendation models (ItemKNN, NeuMF, DMF, NNCF, BPR, BERT4Rec, GRU4Rec, SASRec)
- Classify users based on AUC
- Apply LLM recommendation for weak users
Evaluation and Discussion
Experimental Setup
- Datasets: MovieLens 1M, Amazon Software, Amazon Video Games
- Metric: NDCG@10 (evaluates relevance of top 10 recommendations)
- Comparison: Traditional methods vs proposed hybrid method (with LLMs)
Results
- Accuracy improved across all datasets
- Notable improvement for weak users
- Cost reduction achieved by restricting LLM use
(For detailed quantitative results, please refer to the original paper's tables)
Applications and Future Directions
Potential Applications
- Education: Recommending study materials tailored to learning progress
- Career Support: Suggesting jobs aligned with skills and experience
- Healthcare: Recommending treatments based on symptoms and test results
Business Impact
- Improved customer satisfaction
- Support for acquiring new customers
- Reduced operational costs
Future Challenges
- Refining the definition of weak users
- Enhancing explainability of LLM-based recommendations
Conclusion
This study demonstrates that combining traditional methods with LLMs can achieve a recommendation system that balances fairness and efficiency. It simultaneously improves accuracy for weak users and reduces costs, marking an important step forward in both research and practical application of recommendation systems.
Related Posts
2025-08-08
This paper proposes a novel method called Query-Guided Activation Refilling (ACRE) aimed at improving efficiency and performance in processing long contexts within Large Language Models (LLMs). By combining a two-layer KV cache and query-guided refilling, the approach enables processing of contexts beyond the native context window, significantly enhancing the practicality of long-context information retrieval.
2025-08-08
This paper proposes a novel method, "Desiview," for automatically identifying desirable review comments (DRC) that lead to code changes in code reviews. By constructing a high-quality dataset using Desiview and fine-tuning and aligning the LLaMA model, we demonstrate a significant improvement in DRC generation capability. This approach is expected to greatly contribute to code review automation and software development support.
2025-08-13
This paper proposes a new benchmark, 'Document Haystack,' which measures the ability to find specific information from long documents up to 200 pages long. This benchmark evaluates how accurately a Vision Language Model (VLM) can find intentionally embedded text or image information ('needles') within a document. The experimental results reveal that while current VLMs perform well on text-only documents, their performance significantly degrades on imaged documents or when handling information that combines text and images. This highlights future research challenges in the long-context and multimodal document understanding capabilities of VLMs.