Desiview: A Method for Extracting Desirable Comments to Improve Code Review Quality
2025-08-08
Distilling Desired Comments for Enhanced Code Review with Large Language Models
Authors and Affiliations
- Yongda Yu, Jiahao Zhang, Lei Zhang, Haoxiang Yan, Guoping Rong, Guohao Shi, Dong Shao: Software Institute, Nanjing University
- Haifeng Shen: Faculty of Science and Engineering, Southern Cross University
- Ruiqi Pan, Zhao Tian, Yuan Li, Qiushi Wang: Huawei Technologies Co., Ltd.
Paper Summary
Recent research has increasingly leveraged large language models (LLMs) for automating code reviews. However, existing LLM-based methods face challenges in generating Desired Review Comments (DRC)—comments that actually lead to code modifications. This paper proposes Desiview, a method to automatically identify DRC from code review datasets and construct high-quality datasets. Using these datasets to fine-tune and align LLaMA, we observe substantial improvements in DRC generation capability.
Research Objectives:
- Develop methods to automatically generate high-quality review comments that lead to code changes.
- Create an automated approach to build datasets with a high proportion of DRCs suited for LLM fine-tuning.
Background:
Code review is a critical part of software development but imposes a heavy burden on reviewers. Automating this process with LLMs has gained interest. However, existing LLM-based approaches sometimes generate comments that do not result in code changes, limiting practical usefulness. More effective code review automation requires LLMs that generate comments genuinely leading to code modifications.
Highlights of the Proposed Method
- Desiview: Automatically identifies DRCs by analyzing whether code changes were made following review comments.
- Desiview4FT: A code review model fine-tuned on the high-quality dataset constructed by Desiview, based on LLaMA.
- Desiview4FA: An enhanced version of Desiview4FT further improved by KTO alignment.
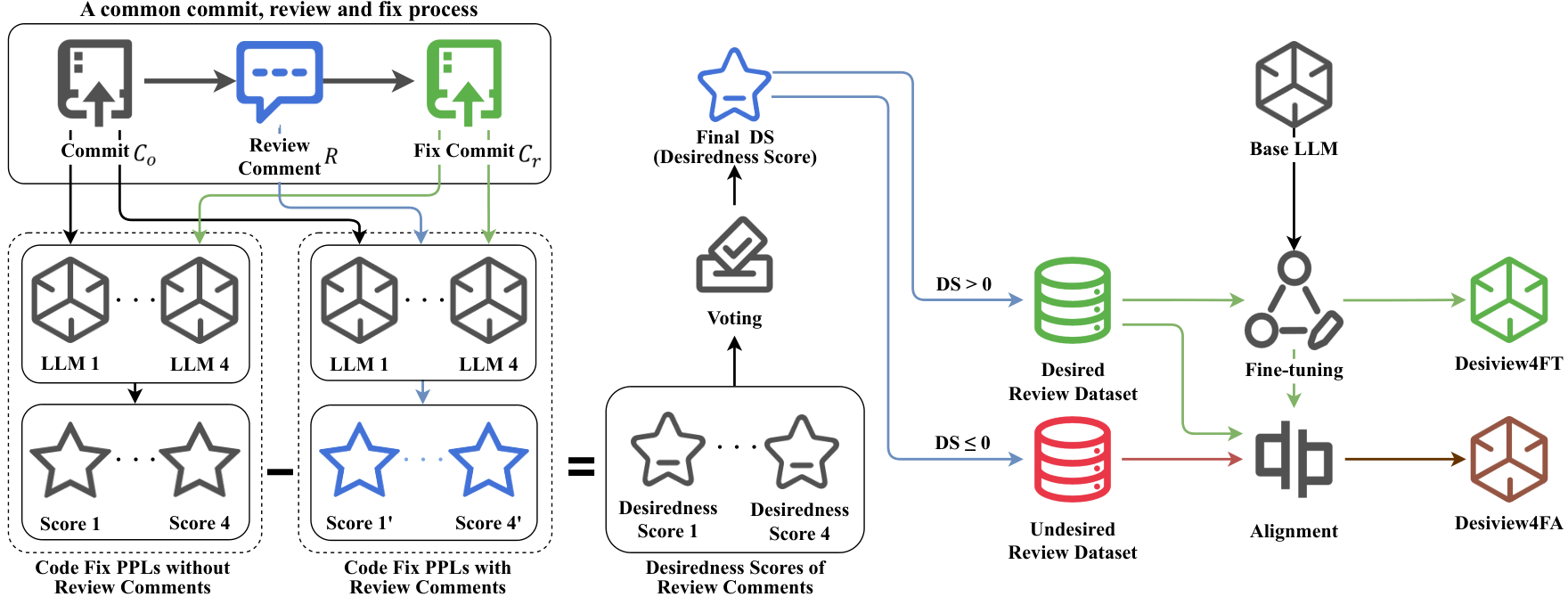
Figure 2: Development process of Desiview4FT and Desiview4FA
Related Work
Automated Code Review
- Defect Detection
- DACE: Uses CNN and LSTM to extract features from code diffs and predict patch quality.
- CodeBERT, CodeT5: Pretrained models for evaluating code quality.
- Review Comment Recommendation/Generation
- CommentFinder: Deep learning-based search for relevant review comments.
- DCR: Learns similarity between commit diffs and review comments to retrieve related comments.
- CodeReviewer: Pretraining tasks focused on defect detection, comment generation, and code repair.
- LLaMA-Reviewer: Fine-tuned LLaMA model achieving strong comment generation performance.
LLM Applications in Software Engineering
- Prompt Engineering:
- CodeT: Guides LLMs to generate test code with ongoing validation.
- MapCoder: Multi-agent prompt system simulating development process tasks.
- Fine-tuning:
- Magicoder: Improves instruction-following ability with diverse data.
- LLaMA-Reviewer: Enhances code review tasks using CodeReviewer dataset.
- RepairLLaMA: Fine-tuned for automatic code repair.
- Alignment:
- RLHF: Learns human preferences with reward models and PPO algorithm.
- DPO: Low-cost alignment by using LLM itself as reward model.
- KTO: Alignment method requiring no paired data.
Novelty and Contributions
Novelty
- Proposed Desiview, an automatic method to identify DRCs from code review datasets.
- Developed Desiview4FT and Desiview4FA, high-performance code review models fine-tuned and aligned using datasets constructed by Desiview.
Contributions
- Advances automation of code review processes.
- Improves performance of software engineering tasks using LLMs.
Method Details
Desiview: Automatic Identification of Desirable Review Comments
1. Identifying DRCs
-
A review comment ( R ) is based on the original code commit ( C_o ) (modeled as ( P(R|C_o) )).
-
Developers respond to ( R ) by making code changes ( C_r ) (modeled as ( P(C_r|C_o, R) )).
-
DRCs are comments that lead to code changes, scored by desirability score (DS):
[ DS = -\bigl( \text{PPL}(P(C_r|C_o, R)) - \text{PPL}(P(C_r|C_o)) \bigr) ]
where PPL is perplexity.
-
If ( DS > 0 ), the comment is judged to contribute to code modification and classified as DRC.
2. Dataset Preparation and Preprocessing
- Used CodeReviewer dataset and computed PPL with four LLMs: CodeLlama-13b-Instruct, starchat2-15b-v0.1, Meta-Llama-3-8B-Instruct, and deepseek-coder-6.7b-instruct.
- The median PPL score across models was taken as the final score for DRC identification.
Desiview4FT: LLM Fine-tuning
- Fine-tuned LLaMA-3 and LLaMA-3.1 on the Desiview-constructed dataset.
- Employed LoRA for efficient resource use.
Desiview4FA: LLM Alignment
- Further improved Desiview4FT using KTO alignment.
- KTO is a paired-data-free method suitable for code review tasks.
Evaluation and Discussion
Evaluation Metrics
- DRC Identification Accuracy: Compared with 10-line rule, GPT-3.5, and GPT-4o.
- Review Comment Quality:
- Automatic evaluation via BLEU-4 scores compared to LLaMA-Reviewer.
- Human evaluation for accuracy in pinpointing issues and descriptive quality.
Results
- Desiview outperformed existing methods in accurately identifying DRCs.
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 10-line rule | 58.33% | 51.92% | 100.00% | 68.35% |
| gpt3.5-turbo-0125 | 68.00% | 60.71% | 81.85% | 69.72% |
| gpt-4o-0513 | 76.50% | 79.72% | 64.07% | 71.05% |
| Desiview | 86.67% | 88.93% | 80.37% | 84.44% |
Table 3: Performance comparison in DRC identification
- LLaMA models fine-tuned and aligned on Desiview datasets showed large improvements in DRC generation.
| Method | BLEU-4 | Human Position (%) | Human Perfect (%) |
|---|---|---|---|
| LLaMA-Reviewer (LLaMA-3) | 8.33 | 70.33 | 16.67 |
| Desiview4FT (LLaMA-3) | 11.87 (+42.5%) | 76.67 (+9.01%) | 18.33 (+9.96%) |
| Desiview4FA (LLaMA-3) | 13.13 (+57.62%) | 80.00 (+13.75%) | 18.67 (+12.00%) |
| LLaMA-Reviewer (LLaMA-3.1) | 6.86 | 68.67 | 12.67 |
| Desiview4FT (LLaMA-3.1) | 12.48 (+81.92%) | 78.67 (+14.56%) | 16.00 (+26.28%) |
| Desiview4FA (LLaMA-3.1) | 13.57 (+97.81%) | 79.00 (+15.04%) | 16.67 (+31.57%) |
Table 4: Performance on code review comment generation
Applications and Future Directions
Potential Applications
- Code review automation tools
- Advanced developer assistance systems
Future Challenges
- Validating applicability to other code review datasets
- Scaling to larger LLMs
- Further improving the quality of generated comments
Glossary
- Large Language Models (LLMs): AI models trained on large text corpora achieving high performance in natural language processing.
- Fine-tuning: Adapting pretrained models to specific tasks.
- Alignment: Adjusting AI outputs to better match human values and intentions.
- Perplexity (PPL): A measure of language model prediction accuracy; lower is better.
- LoRA (Low-Rank Adaptation): Efficient fine-tuning technique for large models.
- KTO (Kullback-Leibler Teacher-student Optimization): A paired-data-free alignment method for LLMs.
- BLEU: Metric evaluating similarity between generated and reference texts, commonly used in machine translation.
Related Posts
2025-08-08
This paper proposes a novel method called Query-Guided Activation Refilling (ACRE) aimed at improving efficiency and performance in processing long contexts within Large Language Models (LLMs). By combining a two-layer KV cache and query-guided refilling, the approach enables processing of contexts beyond the native context window, significantly enhancing the practicality of long-context information retrieval.
2025-08-08
This paper proposes a hybrid Top-k recommendation system that combines traditional recommendation methods with large language models (LLMs). Users are categorized as "active users" and "weak users," with LLMs employed to improve recommendation accuracy and fairness for the latter group. At the same time, the model controls LLM computational costs to ensure practical feasibility.
2025-08-09
Rork is an AI tool that generates native mobile apps from natural language descriptions and supports building and deploying them to the App Store and Google Play. In this article, we share the process and impressions from inputting the requirements of a home life management app into Rork and testing the flow from "generation → functional check → store preparation."