深層学習は皮膚の組織画像から人種を予測できるか? AIの公平性に対する新たな警鐘
2025-08-13
引用:http://arxiv.org/pdf/2507.21912v2
著者と所属
- Shengjia Chen, Ruchika Verma, Jannes Jegminat, Eugenia Alleva, Thomas Fuchs, Gabriele Campanella, Kuan-lin Huang: Windreich Department of Artificial Intelligence and Human Health, Icahn School of Medicine at Mount Sinai, New York, USA など
- Kevin Clare, Brandon Veremis: Department of Pathology, Molecular and Cell-Based Medicine, Mount Sinai Health System, New York, USA
論文概要
この論文「深層学習を用いた皮膚組織画像からの患者自己申告人種の予測」は、計算病理学[注釈1]分野における重要な課題である AIモデルの意図しないバイアス学習 に焦点を当てた研究です。 本研究では、深層学習モデルが病理組織のデジタル画像から、患者が自己申告した人種を予測できるかを検証し、その予測の際にどのような形態学的な「ショートカット」[注釈2]が利用されているかを明らかにしています。
研究の目的: 本研究の主な目的は、深層学習モデルが皮膚の組織画像から人種を識別できるかを検証し、もし可能であれば、その判断根拠となる生物学的な特徴を特定することです。これにより、医療AIが臨床応用される際に、意図しないバイアスによって特定の集団に不利益をもたらすリスクを事前に評価し、対策を講じるための知見を得ることを目指しています。
研究の背景: AI、特に深層学習は、病気の検出や予後予測において目覚ましい成果を上げていますが、その一方で、訓練データに潜むバイアスを学習し、既存の医療格差を助長・増幅させてしまう危険性が指摘されています。X線写真などの医用画像では、AIが専門家にも見分けられない特徴から人種を高精度に予測できることが報告されており、大きな議論を呼んでいます。 しかし、細胞レベルの構造を観察する病理組織画像において、同様の予測が可能かどうかは不明な点が多く残されていました。特に皮膚は、見た目(肌の色)が人種と関連しますが、染色処理された組織標本ではその違いが分かりにくくなるため、AIが何を手がかりにするのかは非常に興味深い問いです。
提案手法のハイライト: 本研究で提案するアプローチの最も重要な点は、アテンションメカニズム[注釈3]を搭載したAIモデルを用いて、人種予測の際にモデルが画像の「どこに注目しているか」を可視化したことです。その結果、AIは**「表皮」**という特定の組織構造を強力な手がかりとして人種を予測していることを突き止めました。これは、AIが疾患そのものではなく、人種と相関する生物学的な特徴を「近道」として学習してしまうリスクを具体的に示した画期的な成果です。
関連研究
先行研究のレビュー
- 医用画像における人種予測: 先行研究では、胸部X線写真やMRI画像から、深層学習モデルが驚くほど高い精度(AUC 0.9以上)で自己申告人種を予測できることが示されています。この能力は、人間の専門家には認識できないレベルの微細な情報に基づいていると推測されています。
- 病理組織画像におけるバイアス: 病理学の分野では、研究施設ごとの染色方法の違いやスキャナの特性(サイトシグネチャ)が民族性と相関し、モデルの性能や公平性に影響を与える可能性が指摘されていました。また、診断タスク用に訓練されたモデルが、意図せず人種情報を学習してしまうことも報告されています。
先行研究と本研究の違い
先行研究が主に放射線画像での人種予測や、病理画像における技術的なバイアスに焦点を当てていたのに対し、本研究は皮膚病理学という特定の分野に絞り込み、人種予測を可能にする**生物学的・形態学的な手がかり(ショートカット)**そのものを特定しようと試みた点で独創的です。単に「モデルが人種を予測できた」と報告するだけでなく、アテンション分析やUMAPによる可視化を通じて、その判断根拠を深く掘り下げています。
論文の新規性と貢献
新規性
本研究は、以下の点で既存の研究と比較して新しい視点を提供しています。
- 新規性1: 皮膚の病理組織画像を用いて、AIモデルが自己申告人種を予測する能力を体系的に調査し、その性能を定量的に評価した世界初の研究の一つです。
- 新規性2: アテンション分析と病理医による形態学的検証を組み合わせることで、予測の根拠となる「表皮」という具体的な生物学的ショートカットを特定しました。
- 新規性3: 疾患の分布といった交絡因子[注釈4]が予測性能に与える影響を明らかにするため、段階的なデータキュレーション(選別・整理)戦略を考案し、その効果を厳密に比較検証しました。
貢献
本研究は、以下の点で学術的および実用的な貢献をしています。
- 貢献1: 計算病理学におけるAIモデルが、疾患とは無関係な人口統計学的情報を学習し、予測の「ショートカット」として利用するリスクを具体的に立証しました。
- 貢献2: 公平な医療AIを開発するためには、単にモデルの性能を追求するだけでなく、慎重なデータ管理と、モデルの判断根拠を解釈する技術が不可欠であることを実証しました。
- 貢献3: AI開発コミュニティに対し、モデルが意図せず学習する可能性のあるバイアスに注意を払うよう警鐘を鳴らし、今後のバイアス緩和研究の重要な基盤を提供しました。
提案手法の詳細
手法の概要
この論文では、Foundation Model(FM)とAttention-based Multiple Instance Learning(AB-MIL)を組み合わせたパイプラインを用いて、皮膚組織画像から人種を分類します。
- Foundation Model (FM)[注釈5]を用いて、組織スライドのデジタル画像(WSI)を多数の小さなタイル画像に分割し、それぞれのタイルから特徴量を抽出します。本研究ではSP22M、UNI、GigaPath、Virchowという4種類の事前学習済みモデルが試されました。
- Attention-based Multiple Instance Learning (AB-MIL)[注釈3]モデルを用いて、全タイルの特徴量を統合し、人種を予測します。この際、アテンションメカニズムによって、予測に重要だったタイルの貢献度(アテンションスコア)が計算されます。
手法の構成
提案手法は、以下のステップで構成されています。
- データ準備とキュレーション: マウントサイナイ医療システムの多様な人種構成を持つ患者集団から、皮膚の病理組織スライドを収集。実験のために、交絡因子を制御する3つのデータセット(無調整、疾患バランス調整、厳密なICDコード基準)を作成しました。
- 特徴抽出: 各スライドを20倍の倍率でタイルに分割し、4種類のFMを用いて各タイルの特徴ベクトルを生成します。
- 分類とアテンションスコア算出: AB-MILモデルを訓練し、スライド全体の人種ラベルを予測させます。同時に、各タイルが予測にどれだけ貢献したかを示すアテンションスコアを算出します。
- 解釈と分析: UMAP[注釈6]を用いて高アテンション領域のタイルを可視化し、病理医がその形態学的特徴(表皮、炎症など)を特定します。さらに、アブレーションスタディ(特定領域の除去実験)を行い、表皮領域の重要性を検証します。
評価・考察
評価方法
- 分析方法: 3つのデータキュレーション戦略(Exp1, Exp2, Exp3)でAIモデルを訓練し、その性能変化を比較分析。
- データセット: マウントサイナイ医療システムの患者2,471人から得られた5,266枚の皮膚組織スライド。データセットは白人、黒人、ヒスパニック/ラティーノ、アジア人、その他の人種グループを含んでいます。
- 評価指標: モデルの分類性能を評価するために、AUC(Area Under the Curve)[注釈7]とバランス精度(Balanced Accuracy)を使用しました。
研究成果
研究の結果、AIが人種を予測できること、そしてその予測がデータに含まれるバイアスに強く影響されることが明らかになりました。
| 実験 | エンコーダー | 白人 | 黒人 | ヒスパニック | アジア人 | その他 | 全体AUC | 全体精度 |
|---|---|---|---|---|---|---|---|---|
| Exp1 | UNI | 0.797 | 0.791 | 0.607 | 0.791 | 0.603 | 0.718 | 0.400 |
| (無調整) | 平均 | 0.789 | 0.770 | 0.596 | 0.795 | 0.563 | 0.702 | 0.394 |
| Exp2 | UNI | 0.760 | 0.773 | 0.560 | 0.715 | 0.569 | 0.676 | 0.380 |
| (疾患バランス調整) | 平均 | 0.742 | 0.754 | 0.560 | 0.724 | 0.574 | 0.671 | 0.364 |
| Exp3 | UNI | 0.819 | 0.766 | 0.654 | 0.556 | 0.594 | 0.678 | 0.296 |
| (厳密なICDコード) | 平均 | 0.799 | 0.762 | 0.640 | 0.570 | 0.543 | 0.663 | 0.302 |
表1: 3つのデータセットキュレーション戦略におけるモデル性能。AUCは1対その他(One-vs-Rest)方式で計算されています。
-
成果1 (バイアスの影響):
- Exp1 (無調整データ): 最も高い全体性能を示しましたが、これはアジア人患者のデータに「痔核」の症例が異常に多かった(61%)という**疾患分布の偏り(バイアス)**が原因でした。モデルは人種そのものではなく、特定の疾患を手がかりに予測していたのです。
- Exp2 & Exp3 (データ調整後): 疾患の偏りを是正すると、特にアジア人グループの予測性能が大幅に低下しました。一方で、白人(AUC 0.799)と黒人(AUC 0.762)のグループでは、バイアスを取り除いた後も高い予測性能が維持されました。これは、これらのグループには疾患とは別の、人種に固有の形態学的特徴が存在することを示唆しています。
-
成果2 (ショートカットの特定):
-
UMAPによる可視化: モデルが予測時に注目した領域(高アテンション領域)をUMAPで可視化したところ、白人・黒人グループで特に「表皮」に対応する領域にアテンションが集中していることが判明しました。
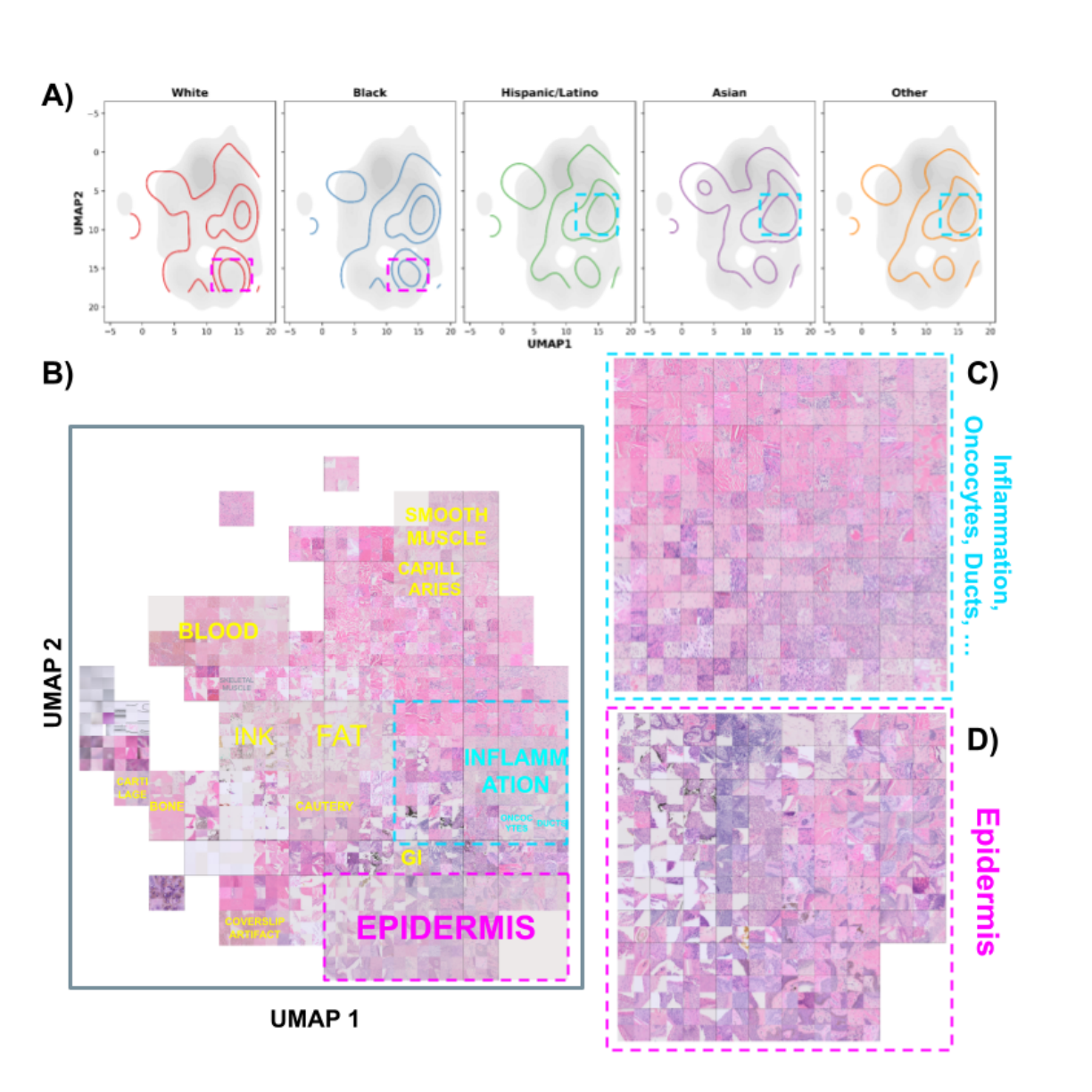 図1: アテンションスコアのUMAP可視化。(A)は各人種グループの高アテンション領域(上位10%)を等高線で示しており、白人(White)と黒人(Black)でアテンションが特定の領域に集中していることが分かります。(B)〜(D)では、高アテンション領域が「表皮(epidermis)」などの特定の組織構造と関連していることが示されています。
図1: アテンションスコアのUMAP可視化。(A)は各人種グループの高アテンション領域(上位10%)を等高線で示しており、白人(White)と黒人(Black)でアテンションが特定の領域に集中していることが分かります。(B)〜(D)では、高アテンション領域が「表皮(epidermis)」などの特定の組織構造と関連していることが示されています。 -
アブレーション(除去)実験: 表皮が予測にどれほど重要かを確かめるため、検証データから意図的に表皮領域のタイルを除去する実験を行いました。
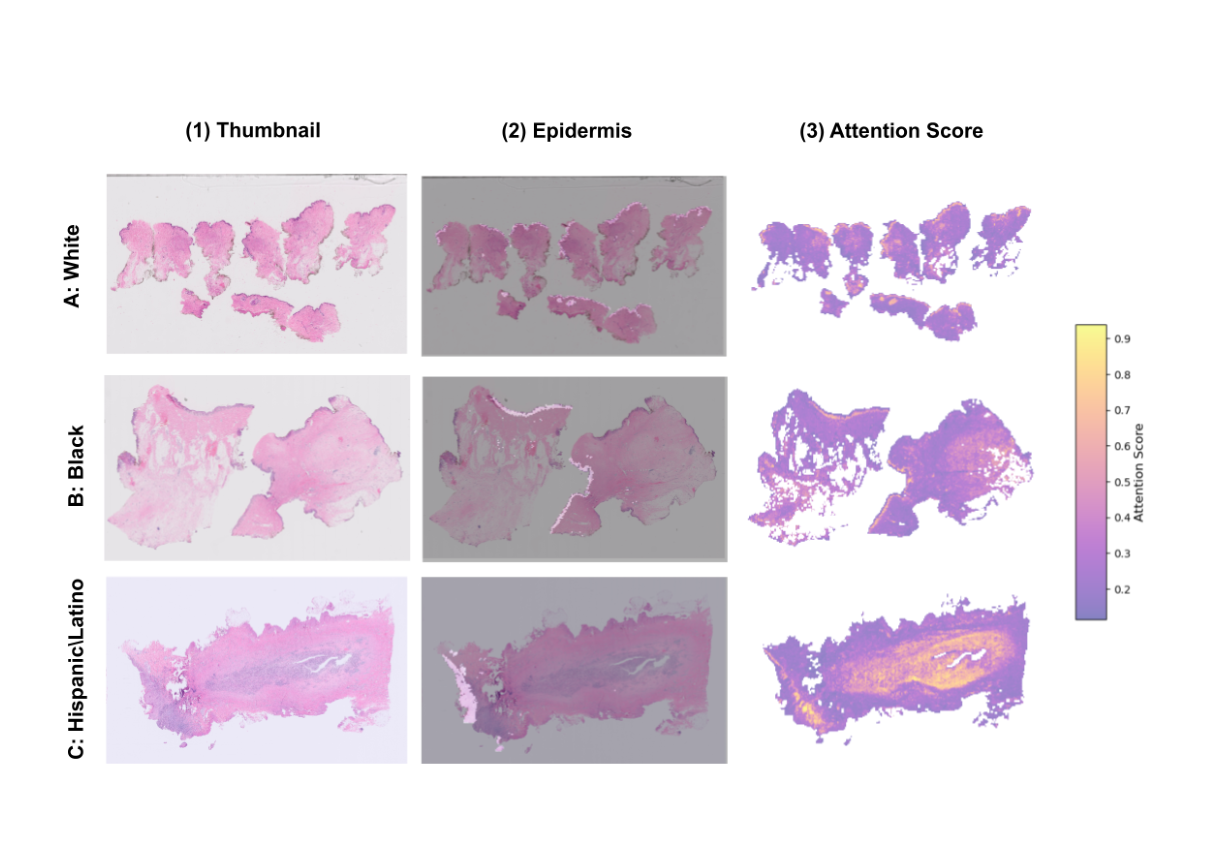 図2: アテンションとアブレーション分析。(A)は表皮領域と非表皮領域のアテンションスコアを比較したもので、多くのグループで表皮がより高い注目を集めていることを示しています。(B)はアブレーション実験の結果で、表皮タイルを除去すると(オレンジ)、元の性能(緑)から大幅に低下し、逆に表皮タイルのみを保持すると(青)、性能が維持されることを示しています。
図2: アテンションとアブレーション分析。(A)は表皮領域と非表皮領域のアテンションスコアを比較したもので、多くのグループで表皮がより高い注目を集めていることを示しています。(B)はアブレーション実験の結果で、表皮タイルを除去すると(オレンジ)、元の性能(緑)から大幅に低下し、逆に表皮タイルのみを保持すると(青)、性能が維持されることを示しています。 -
この結果、表皮領域を除去するとモデルの性能が著しく低下し、逆に表皮領域のみを残しても性能が維持されることが確認されました。これは、AIモデルが「表皮」の形態学的特徴を人種予測の強力なショートカットとして利用している決定的な証拠です。
-
応用例と今後の展望
応用可能性
この研究成果は、直接的な製品やサービスに応用されるものではなく、むしろ医療AIを開発・評価する際の**「ガイドライン」**として極めて重要です。
- AI開発プロセスへの導入: AI開発企業は、モデルの公平性を担保するために、本研究で示されたようなバイアス分析や解釈可能性の手法を開発プロセスに組み込む必要があります。
- 診断支援AIの品質保証: 臨床現場で使われるAIが、疾患とは無関係な患者属性に依存していないかを確認するための、監査ツールとしての活用が期待されます。
ビジネス的展望
本研究は、より信頼性が高く公平なAIを開発するための新しい市場機会を示唆しています。
- バイアス検出・緩和ツールの開発: AIモデルに潜むバイアスを自動で検出し、その影響を緩和する技術やサービスは、今後のAI市場で高い価値を持つ可能性があります。
- 信頼できるAI(Trustworthy AI)のコンサルティング: 医療機関や開発企業に対し、AIの倫理的・社会的なリスクを評価し、対策を提案する専門的なコンサルティングサービスの需要が高まることが予想されます。
今後の課題
本研究は重要な知見をもたらしましたが、いくつかの課題も残されています。
- 遺伝的背景との関連: 自己申告の人種は社会的な側面も含むため、今後は遺伝的祖先データと組み合わせることで、生物学的な要因をより精密に分析する必要があります。
- 他臓器への一般化: 皮膚以外の臓器(例:肺、大腸)の組織画像でも同様の「ショートカット」が存在するのか、さらなる研究が求められます。
- バイアス緩和手法の開発: バイアスの原因となるショートカットを特定した上で、モデルがそれに依存しないように誘導する具体的なバイアス緩和技術の開発が次のステップとなります。
結論
この論文は、深層学習モデルが皮膚の病理組織画像から患者の自己申告人種を、中程度の精度で予測できることを明らかにしました。そして、その予測が疾患分布のようなデータセットの偏りや、「表皮」という組織の形態的な特徴を「ショートカット」として利用することで成り立っている可能性が高いことを突き止めました。
これらの発見は、計算病理学におけるAIモデルを開発・評価する上で、人口統計学的なバイアスを慎重に考慮する必要性を強く示唆しています。公平で信頼性の高い医療AIを実現するためには、モデルが疾患の本質的な特徴を学習しているかを常に検証し、意図しないショートカットに依存するリスクを低減する努力が不可欠です。
注釈
- 注釈1: 計算病理学 (Computational Pathology, CPath): デジタル化された病理組織画像をコンピュータで解析し、がんの診断や予後予測などを支援する研究分野です。
- 注釈2: ショートカット学習 (Shortcut Learning): AIモデルが、タスクを解くための本質的なルールではなく、訓練データに偶然含まれる安易な統計的相関(ショートカット)を学習してしまう現象。これにより、未知のデータに対して性能が著しく低下することがあります。
- 注釈3: Attention-based Multiple Instance Learning (AB-MIL): 大きな画像(スライド全体)を小さなパッチ(タイル)の集合と見なし、予測に重要なパッチに「注意(アテンション)」を向けることで、効率的に学習する手法です。
- 注釈4: 交絡因子 (Confounding Factor): 原因と結果の両方に関連し、両者の見かけ上の関係を生み出してしまう第三の変数のこと。この研究では、「特定の疾患」が「人種」と「AIの予測結果」の両方に関連し、因果関係を誤解させる要因となっていました。
- 注釈5: Foundation Model (FM): インターネット上のテキストや画像など、非常に大規模なデータセットで事前にトレーニングされた汎用的なAIモデル。これを基に特定のタスクを解くことで、高い性能を発揮します。
- 注釈6: UMAP (Uniform Manifold Approximation and Projection): 高次元のデータを、その構造を保ちながら低次元(通常2次元や3次元)に圧縮し、可視化するための技術です。
- 注釈7: AUC (Area Under the Curve): ROC曲線の下の面積を表す値で、分類モデルの性能評価に用いられる指標。値が1に近いほど、モデルの識別能力が高いことを意味します。
関連記事
2025-08-13
本論文は、衛星画像などのリモートセンシングデータを用いた物体検出タスクにおいて、近年注目を集めるTransformerモデルと、従来主流であったCNNモデルの性能を大規模かつ体系的に比較・分析した研究です。3つの異なる特性を持つデータセット上で11種類のモデルを評価し、TransformerがCNNを上回る性能を発揮する可能性と、その際の学習コストとのトレードオフを明らかにしました。
2025-08-13
本論文では、最大200ページに及ぶ長い文書から特定の情報を探し出す能力を測定する新しいベンチマーク「Document Haystack」を提案します。このベンチマークは、文書内に意図的に埋め込まれたテキスト情報や画像情報(「針」)を、Vision Language Model(VLM)がどれだけ正確に見つけ出せるかを評価します。実験の結果、現在のVLMはテキストのみの文書では高い性能を発揮するものの、画像化された文書や、テキストと画像が混在する情報では性能が大幅に低下することが明らかになりました。これは、VLMの長文・マルチモーダル文書理解能力における今後の研究課題を示唆しています。
2025-08-13
本論文は、GoogleのGemini 2.5 Proを活用し、追加学習なしで歩行者の横断意図を予測するゼロショット手法「BF-PIP」を提案します。従来のフレームベースの手法とは異なり、短い連続ビデオと自車速度などのメタデータを直接利用することで、73%という高い精度を達成し、コンテキスト理解に基づく強固な意図予測の可能性を示しました。