コードレビューの質向上を目指した望ましいコメント抽出手法「Desiview」
2025-08-08
Distilling Desired Comments for Enhanced Code Review with Large Language Models
著者と所属
- Yongda Yu, Jiahao Zhang, Lei Zhang, Haoxiang Yan, Guoping Rong, Guohao Shi, Dong Shao: 南京大学ソフトウェア研究所
- Haifeng Shen: サザンクロス大学 理工学部
- Ruiqi Pan, Zhao Tian, Yuan Li, Qiushi Wang: Huawei Technologies Co., Ltd.
論文概要
近年、コードレビューの自動化に大規模言語モデル (LLM) を活用する研究が盛んです。しかし、既存のLLMベースの手法は、コードレビューで実際に修正に繋がる望ましいレビューコメント (Desired Review Comments: DRC) を生成することに課題を抱えていました。本論文では、コードレビューデータセットからDRCを自動的に識別し、質の高いデータセットを構築する手法 Desiview を提案します。この手法で構築したデータセットを用いてLLaMAをファインチューニングおよびアラインメントした結果、DRC生成能力が大幅に向上することを確認しました。
研究の目的:
- コードレビューにおいて、修正に繋がる質の高いレビューコメントを自動生成する手法を開発すること。
- LLMのファインチューニングに適した、DRCの割合が高いデータセットを自動構築する手法を開発すること。
研究の背景:
コードレビューはソフトウェア開発における重要なプロセスですが、レビュアーの負担が大きいという課題があります。そこで、LLMを用いてコードレビューを自動化する試みが注目されています。しかし、既存のLLMベースの手法では、必ずしも修正に繋がるとは限らないコメントが生成される場合があり、実用性に課題がありました。より効果的なコードレビューを実現するためには、実際に修正に繋がるDRCを生成できるLLM が必要とされています。
提案手法のハイライト:
- Desiview: レビューコメントに基づいて実際にコード修正が行われたかどうかを分析し、DRCを自動的に識別する手法。
- Desiview4FT: Desiviewで構築した高品質なデータセットを用いて、LLaMAをファインチューニングしたコードレビューモデル。
- Desiview4FA: Desiview4FTをさらにKTOアラインメントにより性能向上させたコードレビューモデル。
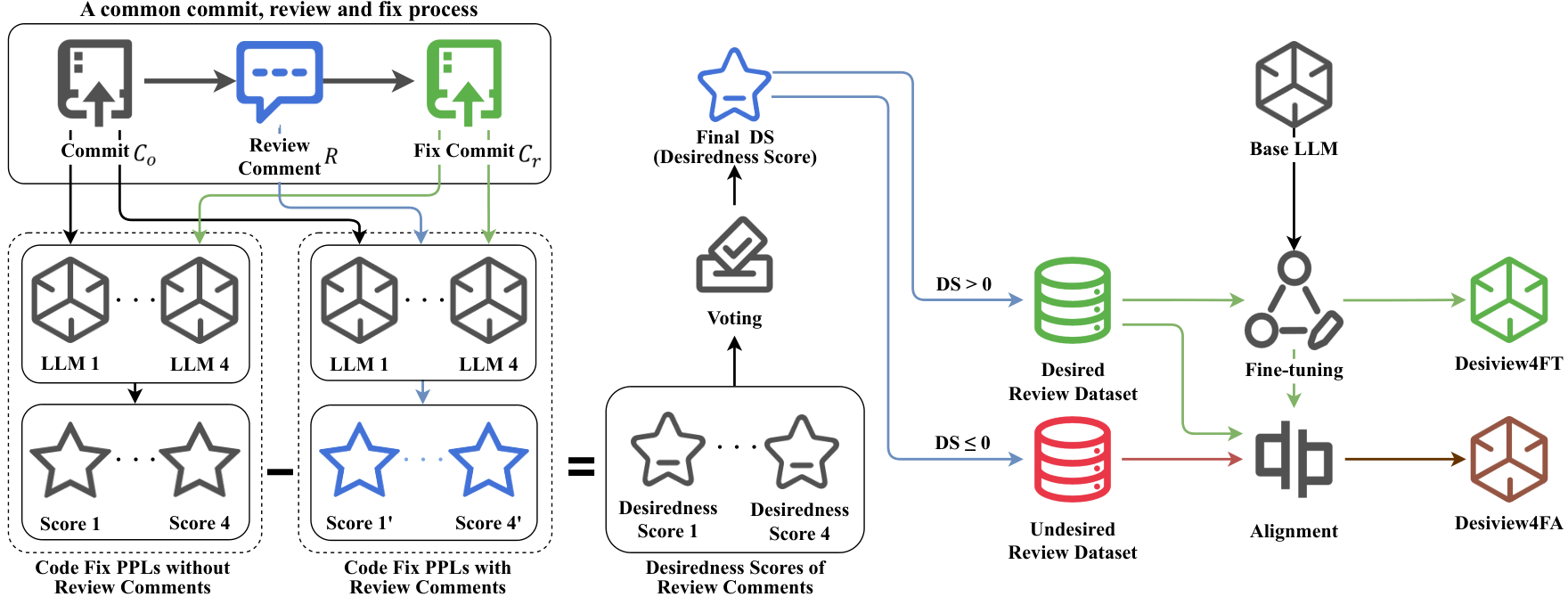
図2: Desiview4FTおよびDesiview4FAの開発プロセス
関連研究
自動コードレビュー
- コードの欠陥検出
- DACE: CNNとLSTMを用いてコードのDiffの特徴を抽出し、コードDiffパッチの品質を予測
- CodeBert, CodeT5: コードの質を評価するための事前学習モデル
- レビューコメントの推薦/生成
- CommentFinder: 深層学習を用いて関連するコードレビューコメントを検索
- DCR: コードコミットDiffとレビューコメントの類似性を学習し、特定のコードコミットに関連するレビューコメントを検索
- CodeReviewer: コードレビューに特化した事前学習タスクを構築し、コード欠陥検出、レビューコメント生成、コード修正で優れた成果
- LLaMA-Reviewer: LLaMAをファインチューニングし、レビューコメント生成で高い性能を実現
ソフトウェアエンジニアリングにおけるLLMの応用
- プロンプトエンジニアリング:
- CodeT: LLMをガイドしてテストコードを生成し、生成コードの精度を継続的に検証
- MapCoder: マルチエージェントプロンプトで開発プロセスの例リコール、計画、生成、デバッグをシミュレート
- ファインチューニング:
- Magicoder: 多様な命令データでLLMの命令コード生成能力を向上
- LLaMA-Reviewer: CodeReviewerデータセットを用いコードレビュータスク性能向上
- RepairLLaMA: LLaMAシリーズをファインチューニングし自動修正機能を提供
- アラインメント:
- RLHF: 報酬モデルで人間の好みを学習し、PPOアルゴリズムでLLMに適用
- DPO: LLM自体を報酬モデルにし低コストでアラインメントを実現
- KTO: ペアデータ不要のアラインメント手法
論文の新規性と貢献
新規性
- コードレビューデータセットからDRCを自動識別する手法 Desiview を提案。
- Desiviewで構築した高品質データセットを用い、LLaMAをファインチューニングおよびアラインメントした高性能コードレビューモデル Desiview4FT および Desiview4FA を開発。
貢献
- コードレビュー自動化への寄与。
- LLMを用いたソフトウェアエンジニアリングタスクの性能向上に貢献。
提案手法の詳細
Desiview: 望ましいレビューコメントの自動識別
1. DRCの識別
-
レビューコメントRは、元のコードコミットCoに基づいて記述される(P(R|Co))。
-
開発者は、レビューコメントRを受けてコード修正Crを行う(P(Cr|Co, R))。
-
DRCは修正に繋がるコメントとし、以下の式で望ましさスコアDSを算出。
DS = −(PPL(P(Cr|Co, R)) − PPL(P(Cr|Co)))
※ PPLはパープレキシティ -
DS > 0ならレビューコメントは修正に貢献しており、DRCと判定。
2. データセットの準備と前処理
- CodeReviewerデータセットを用い、4つのLLM(CodeLlama-13b-Instruct, starchat2-15b-v0.1, Meta-Llama-3-8B-Instruct, deepseek-coder-6.7b-instruct)でPPLを計算。
- 各モデルの結果の中央値を最終スコアに採用し、DRCを識別。
Desiview4FT: LLMのファインチューニング
- Desiviewで構築したデータセットを用い、LLaMA-3およびLLaMA-3.1をファインチューニング。
- リソース軽減のためLoRAを利用。
Desiview4FA: LLMのアラインメント
- Desiview4FTをKTOアラインメントでさらに性能向上。
- KTOはペアデータ不要でコードレビュータスクに適した手法。
評価・考察
評価方法
- DRCの識別精度: 10-line rule、GPT-3.5、GPT-4oと比較
- レビューコメントの質:
- 自動評価:BLEU-4スコアでLLaMA-Reviewerと比較
- 人手評価:問題点の正確な特定および記述精度
研究成果
- Desiviewは既存手法を上回る高精度でDRCを識別。
| Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 10-line rule | 58.33 | 51.92 | 100.00 | 68.35 |
| gpt3.5-turbo-0125 | 68.00 | 60.71 | 81.85 | 69.72 |
| gpt-4o-0513 | 76.50 | 79.72 | 64.07 | 71.05 |
| Desiview | 86.67 | 88.93 | 80.37 | 84.44 |
表3: DRC識別における各手法の性能
- Desiview構築データセットでファインチューニング・アラインメントしたLLaMAはDRC生成能力が大幅向上。
| Method | BLEU-4 | Human Position | Human Perfect |
|---|---|---|---|
| LLaMA-Reviewer (LLaMA-3) | 8.33 | 70.33 | 16.67 |
| Desiview4FT (LLaMA-3) | 11.87 (+42.5%) | 76.67 (+9.01%) | 18.33 (+9.96%) |
| Desiview4FA (LLaMA-3) | 13.13 (+57.62%) | 80.00 (+13.75%) | 18.67 (+12.00%) |
| LLaMA-Reviewer (LLaMA-3.1) | 6.86 | 68.67 | 12.67 |
| Desiview4FT (LLaMA-3.1) | 12.48 (+81.92%) | 78.67 (+14.56%) | 16.00 (+26.28%) |
| Desiview4FA (LLaMA-3.1) | 13.57 (+97.81%) | 79.00 (+15.04%) | 16.67 (+31.57%) |
表4: コードレビューコメント生成タスクの性能
応用例と今後の展望
応用可能性
- コードレビュー自動化ツール
- 開発者支援システムの高度化
今後の課題
- 他のコードレビューデータセットへの適用検証
- より大規模なLLMでの応用
- 生成コメントの質のさらなる向上
注釈
- 大規模言語モデル (LLM): 大量のテキストデータで学習され自然言語処理に高性能を発揮するAIモデル。
- ファインチューニング: 事前学習済みモデルを特定タスク向けに調整する手法。
- アラインメント: 人間の価値観や意図に沿うようAIの出力を調整するプロセス。
- パープレキシティ: 言語モデルの予測性能指標。低いほど精度が高い。
- LoRA (Low-Rank Adaptation): 大規模モデルを効率よくファインチューニングする技術。
- KTO (Kullback-Leibler Teacher-student Optimization): ペアデータ不要のLLMアラインメント手法。
- BLEU: 機械翻訳などで生成文と参照文の類似度を測る評価指標。
関連記事
2025-08-08
本論文は、大規模言語モデル(LLM)における長文コンテキスト処理の効率性と性能向上を目的とし、クエリに基づいて動的に情報を補完する「クエリガイド型アクティベーションリフィル(ACRE)」手法を提案する。二層KVキャッシュとクエリガイド型リフィルを組み合わせることで、ネイティブのコンテキストウィンドウを超える長文処理を可能にし、ロングコンテキスト情報検索の実用性を大きく高めた。
2025-08-08
本稿では、従来の推薦システムと大規模言語モデル(LLM)を組み合わせた ハイブリッドTop-k推薦システムを提案する。ユーザーを「アクティブユーザー」と 「弱ユーザー」に分類し、弱ユーザーにはLLMを用いて推薦精度の向上と 推薦の公平性確保を目指す。同時に、LLMの計算コストを抑制し実用化可能な 推薦モデルを実現した点が特徴である。
2025-08-09
Rorkは自然言語からネイティブなモバイルアプリを生成し、App Store/Google PlayへのビルドとデプロイをサポートするAIツールです。本記事では、家庭向け生活管理アプリの要件を実際にRorkに入力し、「生成→動作確認→ストア準備」までを試した流れと所感をまとめます。